
В далекой-далекой галактике были времена стабильности и процветания. Сервис с шестнадцатью инстансами работал на благо человечества. Через Hibernate он ходил в PostgreSQL-базу, доставал необходимые данные и отдавал другим по REST-интерфейсу. Однако спокойные времена прошли. Внезапно один из инстансов упал с OutOfMemoryError. Лучшие программисты hh.ru пустились в погоню за heapdump-ом в поисках ценнейшей информации.
Привет, меня зовут Артем, я — бэкенд-разработчик в hh.ru. В этой статье расскажу о том, как мы чинили одну из ошибок OutOfMemoryError, которая возникла при работе сервиса с базой данных. Сегодня говорим только на бэкендерском!

Следствие вели эвоки
Мы начали расследование ООМ со скачанного нами heapdump-а. Внимание сразу привлекли неестественно большие размеры SessionFactory, где основной объем занимал query plan cache.

Первое, что приходит в голову — сказать "ха, это какой-то кэш, давайте просто его уменьшим и всё". Но уменьшение кэша не решает исходную проблему, ведь если кэш есть, значит он кому-то нужен, а возможно даже и нам. Так что такое queryPlanCache и с чем его едят?
Мы в hh.ru используем в качестве базы данных PostgreSQL, а в Java-коде общаемся с ней через Hibernate — ORM (Object-Relational Mapping) библиотеку. Hibernate помимо простого мапинга Java объектов на таблицы БД предоставляет ещё несколько удобных инструментов:
Во первых, фреймворк Criteria, который позволяет создавать запросы вообще из чистого Java-кода, накидав разных фильтров и логических условий.
Во вторых, язык для написания запросов — JPQL (пришедший на смену HQL), который в большинстве случаев при работе с ORM является более удобной альтернативой чистому SQL.
Мы довольно активно пользуемся этими возможностями для упрощения себе жизни.
Создали запрос на JPQL или на Criteria — после этого Hibernate должен произвести некоторую магию, чтобы сделать из написанного нами SQL, который сможет понять база. Эта магия зовется "компиляцией запроса".
И логично предположить, что сервис в процессе работы часто выполняет однотипные запросы, и компилировать их каждый раз неоптимально. Для этого и существует queryPlanCache — это кэш скомпилированных запросов, уменьшать его = вредить производительности сервиса.
При компиляции запроса Hibernate:
парсит исходный запрос;
строит абстрактное синтаксическое дерево;
запоминает тип входных и выходных параметров;
готовит стейтмент, который будет транслирован в базу данных.
Когда мы делаем “from User where name = :name“, Hiber строит примерно такое дерево:
SELECT
{derived select clause}
user0_.user_id as user_id1_10_
user0_.first_name as first_na2_10_, user0_.last_name as last_nam3_10_
from
users user0_
where
=
first_name
?И вот такой SQL запрос:
select
user0_.user_id as user_id1_10_,
user0_.first_name as first_na2_10_,
user0_.last_name as last_nam3_10_
from
users user0_
where
first_name=? Мы делаем from User where id in (), где в in передаём коллекцию из 3х элементов:
var ids = List.of(1, 2, 3);
session().createQuery(“from User where id in (:ids)”).setParameter(“ids”, ids);Получаем такое дерево:
SELECT
{derived select clause}
user0_.user_id as user_id1_10_
user0_.first_name as first_na2_10_, user0_.last_name as last_nam3_10_
from
users user0_
where
in
user0_.user_id
{synthetic-alias}
id
inList
?
?
?И вот такой запрос:
select
user0_.user_id as user_id1_10_,
user0_.first_name as first_na2_10_,
user0_.last_name as last_nam3_10_
from
users user0_
where
user0_.user_id in (
? , ? , ?
)Пробуем с коллекцией из 4-х элементов — и вот тут уже обращаем внимание на нечто любопытное, что приближает нас к решению задачи:
SELECT
{derived select clause}
user0_.user_id as user_id1_10_
user0_.first_name as first_na2_10_, user0_.last_name as last_nam3_10_
from
users user0_
where
in
user0_.user_id
{synthetic-alias}
id
inList
?
?
?
?Обратили внимание? Там разное количество вопросительных знаков.
Проблема наносит ответный удар
Дело в том, что с точки зрения Hibernate запросы вида “where in”, куда передано разное количество элементов – это разные запросы. И для каждого из них он построит свое синтаксическое дерево и свой стейтмент.
Допустим, мы делаем получение данных батчами, которые регулируются Java кодом. Батчи, скажем, по 10000 элементов. Размер батча определяет максимальное количество запрашиваемых элементов, но далеко не все батчи будут большими. Где-то прилетает запрос всего на пару элементов, где-то уже на пару сотен, а то и на тысячу. В итоге при неблагоприятном стечении обстоятельств мы можем получить в кэше 10000 абстрактных синтаксических деревьев. Из которых, кстати, будет сгенерировано 10000 стейтментов в базе. И это только из одного запроса!
Стали думать, что с этим можно сделать. Как я уже писал выше, просто уменьшить размер кэша не прокатит, потому что мы получим большую частоту компиляций и не только повысим нагрузку на инстанс, но и увеличим время ответа на запрос в базу.
Также можно уменьшить размер батча. Как временная мера — вполне может сработать. Мы так и сделали, пока разбирались с причиной проблемы. Но нам не хотелось бы сильно дробить наши запросы и получать дополнительный оверхед на ровном месте.
Стали искать решение получше.
Новая надежда
В Hibernate с версией 5.2.18 есть возможность существенно сократить количество планов выполнения в кэше. При включенной настройке “hibernate.query.in_clause_parameter_padding=true” будут генерироваться планы выполнения, в которых количество параметров внутри “where in()” будет приведено к следующей степени двойки.
"This is possible because Hibernate is now padding parameters until the next power of 2 number. So, for 3 and 4 parameters, 4 bind parameters are being used. For 5 and 6 parameters, 8 bind parameters are being used.
Cool, right?"
Vlad Mihalcea
Логичный вопрос: как так? Откуда возьмутся недостающие параметры или куда денутся переданные? Посмотрим прямо в сетевой обмен приложения с базой, выполнив снова запрос с тремя параметрами в “where in” и включенной настройкой:
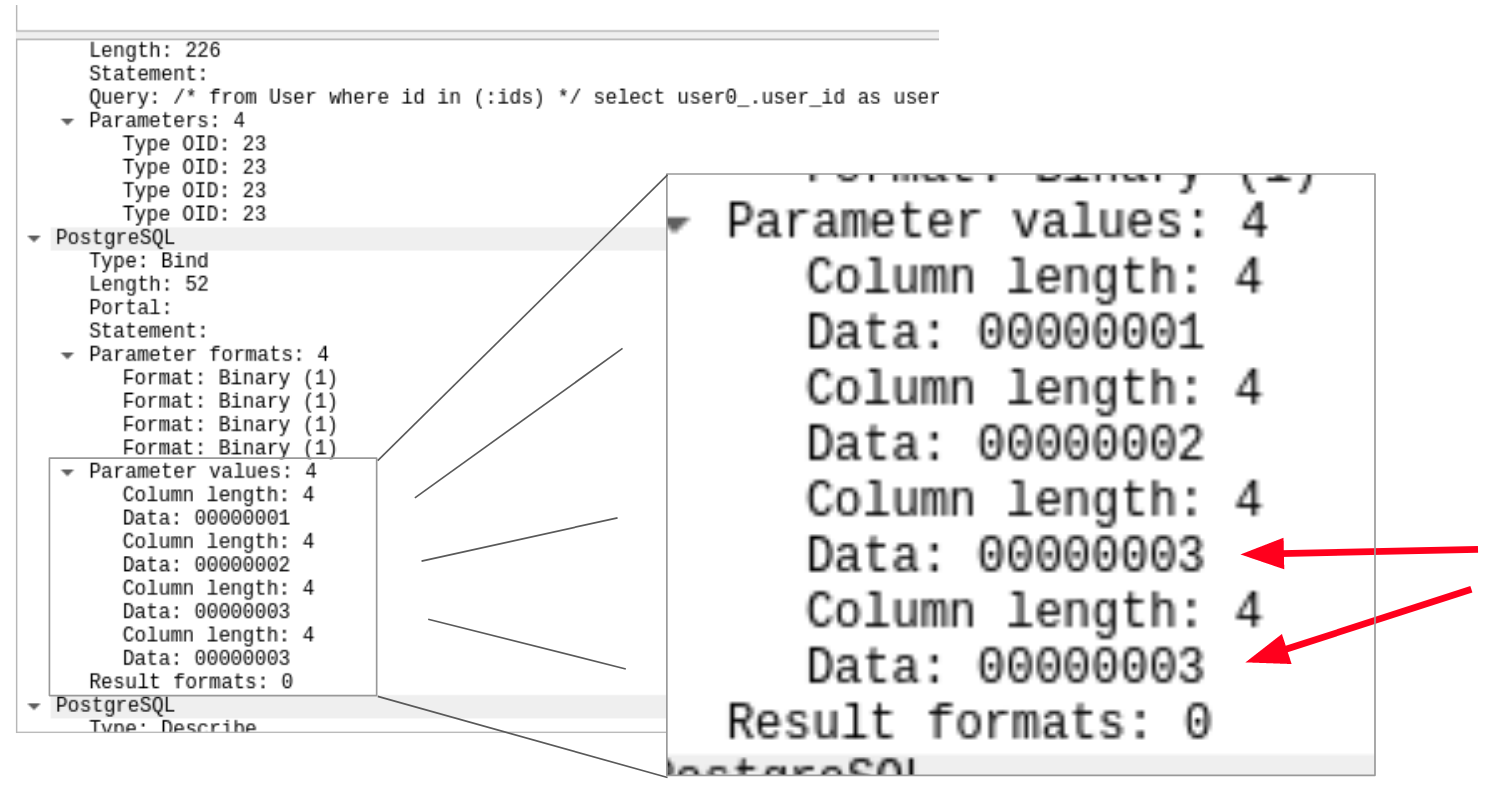
Я отметил стрелками куда смотреть. Hiber просто добавляет последний элемент столько раз, сколько необходимо для формирования нужного количества элементов. В нашем случае добавляется еще один параметр со значением “три”.
Кажется, на этом этапе мы нашли решение проблемы. Включаем настройку — всё работает. Но есть, как говорится, нюансы.
Первый нюанс — это PostgreSQL. Как минимум нашей, 11й версии есть волшебное число 199. При запросе в котором в in передаётся более 199 аргументов база начинает вести себя иначе и иногда можно получить совсем странные планы выполнения на ровном месте. В некоторых случаях в коде мы учитывали этот нюанс, поэтому ограничивали размер батча 199.
Теперь ко включению настройки мы получим увеличение размера батча до следующей степени двойки — это 256. Получается, теперь нам нужно пройтись по всем этим местам в коде и ограничить размер батча до меньшего числа, чтобы у нас получилось 128 и эта настройка его не увеличивала.
Нюанс номер два — это JPA-Criteria. Многие разработчики при работе с ней полагаются на ее внутреннюю логику, на то что она очень умная и сама создаст необходимые переменные во всех нужных местах. Но посмотрим на следующий код:
CriteriaBuilder builder = getSession().getCriteriaBuilder();
CriteriaQuery<User> criteriaQuery = builder.createQuery(User.class);
Root<User> root = criteriaQuery.from(User.class);
List<Integer> ids = List.of(1,2,3);
Predicate wherePredicate = root.get("id").in(ids);
criteriaQuery.select(root).where(wherePredicate);
getSession()
.createQuery(criteriaQuery)
.getResultList();И на дебажный вывод Hiber:
select
user0_.user_id as user_id1_10_,
user0_.first_name as first_na2_10_,
user0_.last_name as last_nam3_10_
from
users user0_
where
user0_.user_id in (
1 , 2 , 3
)Мы передаем в условие “in” массив чисел и Hibernate не стал создавать параметры вовсе. Соответственно, “parameter padding” даже не думает работать — в запрос вставляются просто голые значения. Такое поведение характерно только для коллекции чисел, и у разработчиков Hibernate есть объяснение: числа — это всегда безопасно, это только в строках могут быть SQL-инъекции, поэтому для них создавать параметры и валидировать значение необходимо. Есть одна настройка — literal_handling_mode. Если её установить в значение bind, то Hiber из чисел тоже будет делать параметры. Но сначала посмотрим как будет вести себя коллекция строк.
Передаем в запрос коллекцию строк:
List<String> ids = List.of("Ivan", "Petr", "Obi-Wan");
Predicate wherePredicate = root.get("firstName").in(ids);Получим запрос:
select
user0_.user_id as user_id1_3_,
user0_.first_name as first_na2_3_,
user0_.last_name as last_nam3_3_
from
users user0_
where
user0_.first_name in (
? , ? , ?
)Параметры создаются, но их всё ещё три. Кажется, снова промах. А дело вот в чем: для таких запросов есть специальная фишка — ParameterExpression. Если мы будем передавать параметры в JPA-Criteria именно с использованием ParameterExpression, то дадим Hiber-у понять: из этих параметров нужно всегда создать параметры в SQL-запросе.
Переписываем предыдущий запрос с использованием ParameterExpression:
List<Integer> ids = List.of(1,2,3);
ParameterExpression<Collection> idsExpr = builder.parameter(Collection.class, "ids");
Predicate wherePredicate = root.get("id").in(idsExpr);
criteriaQuery.select(root).where(wherePredicate);
getSession()
.createQuery(criteriaQuery)
.setParameter(idsExpr, ids)
.getResultList();Теперь мы видим в выводе SQL, что нам удалось добиться желаемого результата:
select
user0_.user_id as user_id1_10_,
user0_.first_name as first_na2_10_,
user0_.last_name as last_nam3_10_
from
users user0_
where
user0_.user_id in (
? , ? , ? , ?
)Победа! Осталось только прочитать весь код нашего сервиса и посмотреть, чтобы всё общение с базой данных было в соответствии с вышеизложенным.
Заключение
В результате проведенных исследований после одного OutOfMemoryError мы произвели достаточно большой рефакторинг кода, где устранили сразу несколько проблем.
во-первых, мы включили настройку in_clause_parameter_padding, с помощью которой значительно уменьшили размер query plan cache.
во-вторых, просмотрели все места, где у нас производится забор данных батчами, и скорректировали размер таковых.
и в-третьих, мы перепроверили все использования JPA-критерии, чтобы параметры всегда передавались через ParameterExpression.
Теперь на графики любо-дорого смотреть. Мы уменьшили размер кэша с 328 до 6 мегабайт и мы практически устранили промахи query plan cache.
Да пребудет с вами Сила!
Сцена после титров
Описанное в статье — сложно и не всегда очевидно. От такого можно быстро устать. Однако существуют еще и noCode-решения. Мы сейчас исследуем эту штуку и нам нужна ваша помощь.
Пожалуйста, пройдите короткий опрос из 6 пунктов и расскажите о ваших отношениях с noCode-инстурментами. Спасибо!
