Latest Blog Posts
PGTT Extension for Global Temporary Tables in PostgreSQL
Posted by Gilles Darold in HexaCluster on 2024-06-10 at 14:30
Customers migrating from Oracle to PostgreSQL and SQL Server to PostgreSQL are often curious of Oracle compatibility and SQL Server compatibility in PostgreSQL. Best way to solve most of the Oracle or SQL Server compatibility is through some of the popular extensions in PostgreSQL. I have had a chance to contribute to multiple such tools […]
The post PGTT Extension for Global Temporary Tables in PostgreSQL appeared first on HexaCluster.
CloudNativePG Recipe 8: Participating in PostgreSQL 17 Testing Program in Kubernetes
Posted by Gabriele Bartolini in EDB on 2024-06-10 at 13:09
Join the PostgreSQL 17 testing program using Kubernetes and CloudNativePG! With the recent release of PostgreSQL 17 Beta 1, our community has made operand container images available for testing. This article guides you through deploying a PostgreSQL 17 cluster, selecting specific Debian versions, and verifying installations. Perfect for developers in early stages, your participation will help identify and fix bugs before the final release. Get involved and ensure PostgreSQL 17 is robust and ready for production, even in Kubernetes!
… or thanks to Kubernetes! ;)
🎙️ IndieRails Podcast — Andrew Atkinson - The Postgres Specialist
Posted by Andrew Atkinson on 2024-06-10 at 00:00
I loved joining Jeremy Smith and Jess Brown as a guest on the IndieRails podcast!
I hope you enjoy this episode write-up, and I’d love to hear your thoughts or feedback.
Early Career
I got my start in programming in college, and my first job writing Java. This was the mid 2000s so this was Java Enterprise Edition, and I worked in a drab, boring gray cubicle, like Peter has in the movie Office Space.
I was so excited though to have a full-time job writing code as an Associate Software Engineer. For me this validated years of work learning how to write code in college, represented a huge pay increase, and felt like something I could make a career out of.
Build a Blog in 15 Minutes
Somewhere along the way I saw the Ruby on Rails 15-minute build a blog video. This was a turning point for me, seeing what, and how an individual developer could build a full-stack web app.
Train Brain
Later in the 2000s, I took a side mission from Ruby on Rails, and taught myself Objective-C and iOS, and launched an app for train riders in Minneapolis. I called the app Train Brain and partnered with Nate Kadlac who designed the app icon, and all of the visuals for the app and website. Nate turned out to be a great connection, as we’ve remained friends over the years. When I asked Nate to do the cover illustration for my book, I was thrilled to hear it would work out because I know Nate is a talented designer, but also because I think we both love to support each other how we can.
Spicy Chicken at Wendy’s
I told a story of learning Ruby on Rails using the Michael Hartl book: RailsSpace. This was a favorite book of mine, because it had readers build a social networking app, which was a hot space to be in at the time. Readers built the app up as they went along, which is a great way to learn any new technology! I was working in a job I wasn’t loving out in the suburbs at this point, and didn’t really have work friends. On my lunch breaks, I’d take lunch myself at Wendy’s, and my usual order was a s
[...]Exploring PostgreSQL 17: A Developer’s Guide to New Features – Part 1 – PL/pgSQL
Posted by Deepak Mahto on 2024-06-08 at 12:53
PostgreSQL 17 Beta was released on May 23, 2024, introducing a host of exciting new features anticipated to be part of the official PostgreSQL 17 release. In this blog series, we’ll delve into these features and explore how they can benefit database developers and migration engineers transitioning to the latest PostgreSQL version.
First part of the blog is on newer features with PL\pgSQL – Procedural language in PostgreSQL 17.
PL/pgSQL is the default procedural language preinstalled on PostgreSQL whenever a new database is created. It is a loadable procedural language that follows a block-based structure, making it easier to wrap functional logic in stored code as functions or procedures.
As part of the PostgreSQL 17 Beta release, the following additions have been made to PL/pgSQL:
- Allow plpgsql %TYPE and %ROWTYPE specifications to represent arrays of non-array types (Quan Zongliang, Pavel Stehule)
- Allow plpgsql %TYPE specification to reference composite column (Tom Lane)
New Array Type Declarations in PL/pgSQL with PostgreSQL 17
With PostgreSQL 17, we can now directly declare array types based on the primitive type of columns, or using row types from tables or user-defined types with %TYPE or %ROWTYPE.
Prior to PostgreSQL 17, if we needed to declare an array variable, we couldn’t use %TYPE or %ROWTYPE to refer to the underlying database type. Instead, we had to manually note the underlying data type and use it explicitly in the array declaration.
PostgreSQL 17 simplifies this process. Now, using %TYPE and %ROWTYPE, we can define array variables based on the types of underlying database objects like columns, tables, or user-defined types. Moreover, we can similarly declare additional array variables using underlying variables types.
Lets create a sample table and type to understand with an sql snippet.
--PostgreSQL 17 Beta
create table testplpgsql17
as
select col1, col1::text as col2, col1*9.9 as col3
from generate_series(1,10) as col1;
create PGSQL Phriday #017
Posted by Ryan Booz on 2024-06-07 at 20:12
Invitation from James Blackwell-Sewell
I had the unexpected pleasure of meeting James when we worked together at Timescale. He’s a delightful chap, a great teacher and mentor in all things Postgres, and continues to help push things forward in the world of time-series data on the most advanced open-source, relational database in the world! 
The challenge is below, but I have one bonus I’d like to invite folks to add as they publish. Who can create the coolest elephant image with AI to match their post? 
The Challenge
This week I’ve been given the honor of hosting PGSQL Phriday, and I’d like to hear some opinions on the largest elephant in the room (and it’s not Slonik this time!): Artificial Intelligence.
We are in the middle of an AI Summer, with bigger and bigger advances every month. Almost every company, every product, and seemingly every developer, has their own opinion on what’s happening and why it’s important in their own corner of the tech world. But how does all this relate to our beloved PostgreSQL? I’d love to see blog posts from anyone and everyone that has thoughts on the two key questions below.
I know a lot of products, extensions, and startups already exist in this space, I’d love to hear what you’re all up to! As always, counterpoints are welcome, if you’ve got concerns about AI and PostgreSQL, let us know.
Performance impact of using ORDER BY with LIMIT in PostgreSQL
Posted by semab tariq in Stormatics on 2024-06-07 at 19:13
Learn how the combination of ORDER BY and LIMIT clauses in PostgreSQL affects query performance, and discover optimization techniques to maintain efficient database performance and fast query responses.
The post Performance impact of using ORDER BY with LIMIT in PostgreSQL appeared first on Stormatics.
SQL/PGQ and graph theory
Posted by Ashutosh Bapat on 2024-06-07 at 10:33
More complex log in json format processing
Posted by Pavel Stehule on 2024-06-07 at 05:34
I needed to summarize number of bugs per week per user
cat postgresql-*.json | \
jq -r 'select(.error_severity=="ERROR") | select (.application_name | (startswith("pgAdmin") or startswith("IntelliJ"))) ' | \
jq -rs 'group_by (.user, .message) | map({user: .[0].user, message: .[0].message, count: length}) | .[] | [.count, .user, .message] | @tsv'
I had to learn so grouping inside jq is allowed only on json array (and result is an array again), so I needed to merge input records to array by using -s, --slurp option. For final processing, I need to translate result array just to set of records by syntax .[]. Transformation to tsv (tab separated data) are used for better readability than csv.
2024.pgconf.dev and Growing the Community
Posted by Robert Haas in EDB on 2024-06-06 at 19:01
I think 2024.pgconf.dev was a great event. I am really grateful to the organizing team for all the work that they did to put this event together, and I think they did a great job. I feel that it was really productive for me and for the PostgreSQL development community as a whole. Like most things in life, it was not perfect. But it was really good, and I'm looking forward to going back next year. It was also a blast to see Professor Margo Seltzer again; I worked for her as a research assistant many years ago. She gave a wonderful keynote.
Read more »Deep Dive into PostgREST - Time Off Manager (Part 3)
Posted by Radim Marek on 2024-06-06 at 00:00
This is the third and final instalment of "Deep Dive into PostgREST". In the first part, we explored basic CRUD functionalities. In the second part, we moved forward with abstraction and used the acquired knowledge to create a simple request/approval workflow.
In Part 3, we will explore authentication and authorisation options to finish something that might resemble a real-world application.
Authentication with pgcrypto#
There's no authorisation without knowing user identity. So let's start there. Our users table from the first part had an email to establish the identity, but no way to verify it. We will address this by adding a password column. Of course, nobody in their right mind would store passwords in plain text.
To securely store users' passwords, we are going to utilise PostgreSQL pgcrypto extension (documentation). This built-in extension provides a suite of cryptographic functions for hashing, encryption, and more. In our case, we will leverage crypt with the gen_salt function to generate password hash using bcrypt algorithm.
Let's start with loading the extension and adding password column:
CREATE EXTENSION IF NOT EXISTS pgcrypto;
ALTER TABLE users ADD COLUMN password_hash TEXT NOT NULL DEFAULT gen_salt('bf');
The new column password_hash will accommodate the variable-length bcrypt hash, while default function gen_salt('bf') creates a unique bcrypt salt for every user.
Now that our table structure is set, let's see how we can securely set and verify passwords using pgcrypto.
When a user sets or changes their password, we'll hash it using crypt before storing it in the password_hash column.Here's how:
UPDATE users SET password_hash = crypt('new_password', gen_salt('bf')) WHERE email = 'user@example.com';
and during login, we will verify the hash of the password the user enters with the stored password_hash:
SELECT user_id FROM users WHERE email = 'user@example.com' AND password_hash = crypt('entered_password', password_hash);
JWT Authentication#
With th
[...]Administering a Patroni Managed PostgreSQL Cluster
Posted by Robert Bernier in Percona on 2024-06-05 at 12:58
 There are quite a number of methods these days for installing Patroni. I want to discuss the next step, which is how to start tuning a running system.The manner of updating a running Postgres server typically involves editing the standard Postgres files: postgresql.conf postgresql.auto.conf pg_hba.conf Working with a Patroni HA cluster, one has the added […]
There are quite a number of methods these days for installing Patroni. I want to discuss the next step, which is how to start tuning a running system.The manner of updating a running Postgres server typically involves editing the standard Postgres files: postgresql.conf postgresql.auto.conf pg_hba.conf Working with a Patroni HA cluster, one has the added […]
Ultimate Guide to POSETTE: An Event for Postgres, 2024 edition
Posted by Claire Giordano in CitusData on 2024-06-05 at 06:06
Now in its 3rd year, POSETTE: An Event for Postgres 2024 is not only bigger than previous years but some of my Postgres friends who are speakers tell me the event is even better than past years. Sweet.
Formerly called Citus Con (yes, we did a rename), POSETTE is a free and virtual developer event happening Jun 11-13 that is chock-full of Postgres content—with 4 livestreams, 42 talks, and 44 speakers.
And while POSETTE is organized by the Postgres team here at Microsoft, there is a lot of PG community involvement. For example, 31 of the 44 speakers (~70%) are from outside Microsoft! We have also tried to be quite transparent about the talk selection process used for POSETTE 2024, if you’re curious.
On the schedule, the add to calendar links (in upper right of each livestream's tab) are quite useful for blocking your calendar—and the calendar appointments include a link to where you can watch the livestreams on the POSETTE site.
So what exactly is on the schedule for POSETTE: An Event for Postgres 2024? A lot! When you look at the schedule page, be sure to check out all 4 tabs, so you don’t miss all the unique talks in Livestreams 2, 3, and 4.
There’s something “accessible” about virtual events
As much as many of us 🧡 in-person Postgres events—I just returned from PGConf.dev 2024 in Vancouver which was so much fun1—I am also a big fan of the accessibility of the virtual format.
- Why? Because not everybody can travel to in-person conferences: Not everyone has the budget (or the time, or the schedule flexibility). So it’s rewarding to collaborate with all these knowledgeable speakers to produce video talks you can watch from the comfort of your very own desk. With espresso (or tea) in hand.
Speaking of accessibility, let's talk captions. All the talk videos published on YouTube will have captions available in 14 lan
[...]Reliable Backups in PostgreSQL – Another Critical Requirement for Financial Organizations
Posted by Umair Shahid in Stormatics on 2024-06-04 at 12:07
Learn how reliable backups in PostgreSQL can help financial organizations maintain data integrity, comply with regulations, and ensure business continuity.
The post Reliable Backups in PostgreSQL – Another Critical Requirement for Financial Organizations appeared first on Stormatics.
Foreign keys in PostgreSQL: Circular dependencies
Posted by Hans-Juergen Schoenig in Cybertec on 2024-06-04 at 05:29
Relational databases provide one very essential functionality which is key to integrity, data quality and consistency: foreign keys. If you want to build a professional application that relies on correct data, there is basically no way around the concept of referential integrity. The same is, of course, true in PostgreSQL.
Foreign keys and circular dependencies
However, there is a corner case many people are not aware of: circular dependencies. Now, how can that ever happen? Consider the following example which has been tested in PostgreSQL:
CREATE TABLE department (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name text NOT NULL UNIQUE,
leader bigint NOT NULL
);
CREATE TABLE employee (
id bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name text NOT NULL,
department bigint REFERENCES department NOT NULL
);
ALTER TABLE department
ADD FOREIGN KEY (leader) REFERENCES employee;
In this case, we want to store departments and employees. Every department will need a leader, and every employee will need a department. We cannot have a department without a department leader - but we cannot have an employee without a department either.
The problem which arises is that we cannot insert into those two tables anymore without violating the foreign keys. The next listing shows what happens:
INSERT INTO department (name, leader) VALUES ('hans', 1);
ERROR: insert or update on table "department" violates
foreign key constraint "department_leader_fkey"
DETAIL: Key (leader)=(1) is not present in table "employee".
The problem is the same if we start to insert into the other table first - both operations will cause a similar error, so we are basically stuck with two tables into which we cannot insert any data.
INITIALLY DEFERRED coming to the rescue
The solution to the problem is to use “INITIALLY DEFERRED”. The idea is simple. Consider the following constraint inst
[...]How engaging was PGConf.dev really?
Posted by Peter Eisentraut in EDB on 2024-06-04 at 04:00
PGConf.dev 2024 is over. What happened while no one was watching the source code?
Nothing!
Last Friday I posted:
After that, I was up all night (not really) trying to compute this correctly in SQL. And then I figured I might as well wait until the streak is broken, which has happened now.
Here is what I came up with.
First, load a list of all commits into a table.
create table commits (
id int generated always as identity,
hash varchar,
commitdate timestamp with time zone
);
git log --reverse --format='format:%h%x09%ci' | psql -c 'copy commits (hash, commitdate) from stdin'
(This is using the “committer date” from Git, which is not necessarily exactly equal to the time the commit was made or pushed, or could be faked altogether. But let’s ignore that here; this is not a forensic analysis but just a bit of fun.)
Now compute for each commit the duration since its previous commit:
select c1.hash,
c2.commitdate,
c2.commitdate - c1.commitdate as gap_since_prev
from commits c1 join commits c2 on c1.id = c2.id - 1
order by gap_since_prev desc
fetch first 20 rows only;
Result:
hash | commitdate | gap_since_prev
-------------+------------------------+------------------
28fad34c7bb | 1996-09-10 06:23:46+00 | 12 days 07:21:03
94cb3fd8757 | 2001-07-29 22:12:23+00 | 7 days 00:11:19
37168b8da43 | 2000-08-19 23:39:36+00 | 6 days 20:49:01
8fea1bd5411 | 2024-06-03 17:10:43+00 | 6 days 12:49:30 -- pgconf.dev 2024
0acf9c9b284 | 1997-06-20 02:20:26+00 | 6 days 12:11:38
75ebaa748e5 | 1997-07-08 22:06:46+00 | 6 days 07:53:32
c5dd292007c | 1996-09-16 05:33:20+00 | 5 days 22:41:52
41b805b9133 | 1997-07-21 22:29:41+00 | 5 days 20:04:25
577b0584aa9 | 1997-10-09 04:59:37+00 | 5 days 05:48:11
4b851b1cfc6 | 1997-08-12 20:16:25+00 | 4 days 16:24:52
cbdda3e2a94 | 2003-07-14 10:16:45+00 | 4 days 16:18:58
19740e2fff2 | 1998-12-04 15:34:49+00 | 4 days 15:04:44
a1480ec1d3b | 2015-10-27 16:20:40+00 | 4 days 14:19:29
053004a80b5 | 1998pgsql_tweaks 0.10.4 released
Posted by Stefanie Janine on 2024-06-03 at 22:00
pgsql_tweaks is a bundle of functions and views for PostgreSQL
The soucre code is available on GitLab, a mirror is hosted on GitHub.
One could install the whole package, or just copy what is needed from the source code.
The extension is also available on PGXN.
General changes
In this release has been tested against PostgreSQL 17 beta 1..
There have been no new or changed features, therefore this is only a minor release.
Controlling Resource Consumption on a PostgreSQL Server Using Linux cgroup2
Posted by Jobin Augustine in Percona on 2024-06-03 at 17:03
 Multi-tenancy/co-hosting is always challenging. Running multiple PG instances could help to reduce the internal contention points (scalability issues) within PostgreSQL. However, the load caused by one of the tenants could affect other tenets, which is generally referred to as the “Noisy Neighbor” effect. Luckily, Linux allows users to control the resources consumed by each program […]
Multi-tenancy/co-hosting is always challenging. Running multiple PG instances could help to reduce the internal contention points (scalability issues) within PostgreSQL. However, the load caused by one of the tenants could affect other tenets, which is generally referred to as the “Noisy Neighbor” effect. Luckily, Linux allows users to control the resources consumed by each program […]
RAG app with Postgres and pgvector
Posted by Gülçin Yıldırım Jelínek in EDB on 2024-06-03 at 10:53
Terminal Tools for PostGIS
Posted by Dian Fay on 2024-06-02 at 00:00
Of late, I've been falling down a bunch of geospatial rabbit holes. One thing has remained true in each of them: it's really hard to debug what you can't see.
There are ways to visualize these. Some more-integrated SQL development environments like pgAdmin recognize and plot columns of geometry type. There's also the option of standing up a webserver to render out raster and/or vector tiles with something like Leaflet. Unfortunately, I don't love either solution. I like psql, vim, and the shell, and I don't want to do some query testing here and copy others into and out of pgAdmin over and over; I'm actually using Leaflet and vector tiles already, but restarting the whole server just to start debugging a modified query is a bit much in feedback loop time.
So: new tools. You need zsh, psql, and per usual, ideally a terminal emulator that can render images. I use wezterm but the only thing you'd need to change is the sole wezterm imgcat call in each. Both can also pipe out to files.
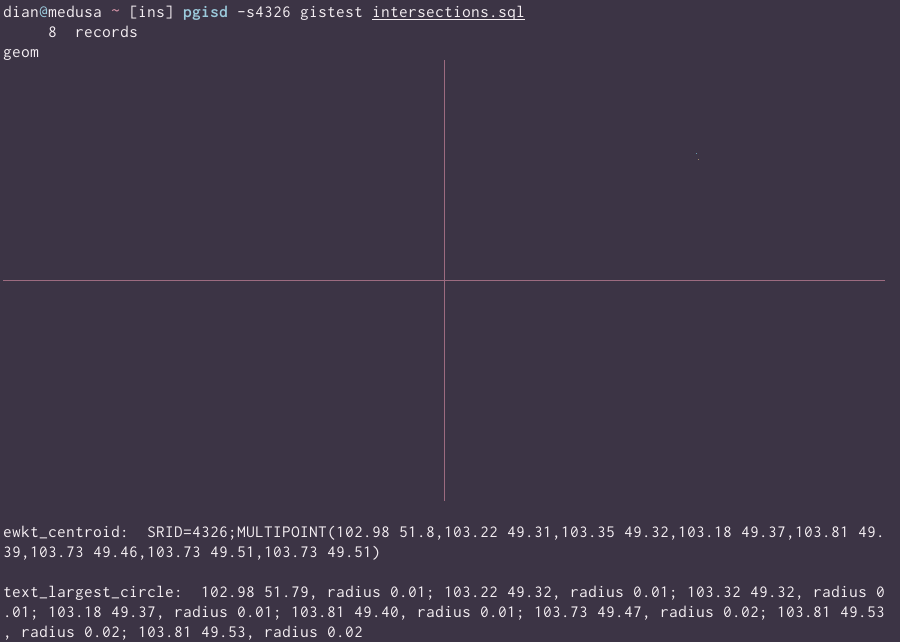
pgisd
The first one, and the tool I used to create the images in the fluviation post. pgisd runs the given SQL script and renders geometry or geography columns in the output. (It actually has to run the query twice, in order to detect and build rendering code for each geom column)
I have some small polygons dumped from rasters, filtered, intersected, sliced, diced, et cetera. My script looks like this:
select
geom,
st_asewkt(st_centroid(geom)) as ewkt_centroid,
format(
'%1$s %2$s, radius %3$s',
round(st_x((st_maximuminscribedcircle(geom)).center)::numeric, 2),
round(st_y((st_maximuminscribedcircle(geom)).center)::numeric, 2),
round((st_maximuminscribedcircle(geom)).radius::numeric, 2)
) as text_largest_circle
from lots_of_ctesWithout specifying a bounding box, you can barely pick out a couple of dots near where Mongolia would be on a WGS84 projection, given that the whole thing has been squeezed into some 800ish pixels wide:
Enhance:
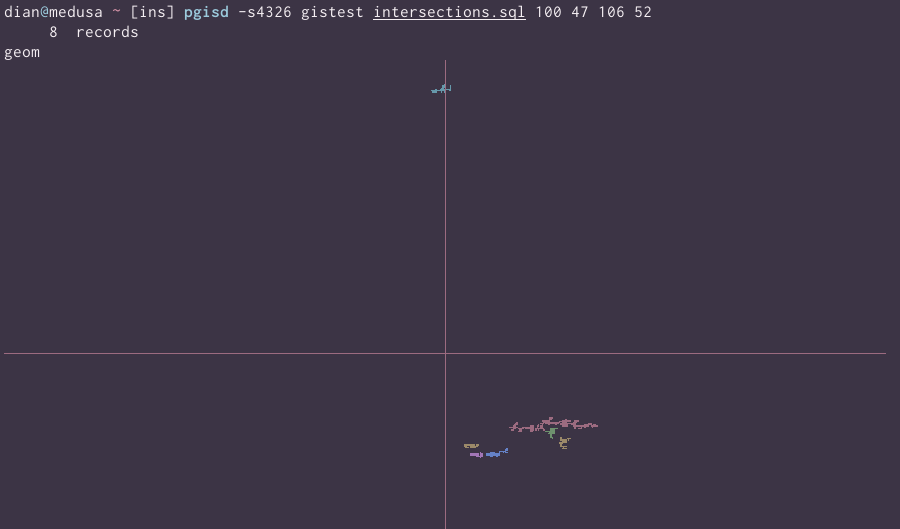
Tweak the where clause to skip tha
PG Phriday: Taking Postgres for GRANTed
Posted by Shaun M. Thomas in Tembo on 2024-05-31 at 12:00
Introducing pgCompare: The Ultimate Multi-Database Data Comparison Tool
Posted by Brian Pace in Crunchy Data on 2024-05-31 at 10:00
In the evolving world of data management, ensuring consistency and accuracy across multiple database systems is paramount. Whether you're migrating data, synchronizing systems, or performing routine audits, the ability to compare data across different database platforms is crucial. Enter pgCompare, an open-source tool designed to simplify and enhance the process of data comparison across PostgreSQL, Oracle, MySQL, and MSSQL databases.
The key features of pgCompare:
- Multi-Database support: pgCompare stands out with its ability to connect and compare data across four major database systems: PostgreSQL, Oracle, MySQL, and MSSQL. This multi-database support is crucial for organizations managing a variety of database technologies.
- Comparison report: pgCompare generates detailed reports highlighting the differences between datasets. These reports include information about missing records, mismatched values, and summary statistics, enabling users to quickly identify and address inconsistencies.
- Stored results: Results are stored in a Postgres database for tracking historical compares, current status, and alerting.
- Flexible comparison options: Users can customize their comparisons with various options such as transforming data and excluding specific columns. This flexibility ensures that comparisons are tailored to meet specific requirements.
- Performance and scalability: Built with performance in mind, pgCompare efficiently handles large datasets with minimal impact to source and target systems. Its flexible architecture ensures that it can meet the needs of both small and large datasets.
Getting Started with pgCompare
PgCompare is an open source tool, free to use for anyone, and getting started with pgCompare is simple. The tool can be downloaded from the official git repository, https://github.com/CrunchyData/pgCompare, where users will find detailed documentation and tutorials to help them configure and run their first comparisons. With its robust feat
[...]Setting Up a High Availability 3-Node PostgreSQL Cluster with Patroni on Ubuntu 24.04
Posted by semab tariq in Stormatics on 2024-05-30 at 12:00
Learn how to set up a high-availability 3-node PostgreSQL cluster with Patroni on Ubuntu 24.04, ensuring your database is always online and resilient to failures.
The post Setting Up a High Availability 3-Node PostgreSQL Cluster with Patroni on Ubuntu 24.04 appeared first on Stormatics.
Data Encryption in Postgres: A Guidebook
Posted by Greg Nokes in Crunchy Data on 2024-05-30 at 10:00
When your company has decided it's time to invest in more open source, Postgres is the obvious choice. Managing databases is not new and you already have established practices and requirements for rolling out a new database. One of the big requirements we frequently help new customers with on their Postgres adoption is data encryption. While the question is simple, there's a few layers to it that determine which is the right approach for you. Here we'll walk through the pros and cons of approaches and help you identify the right path for your needs.
Overview of At-Rest Encryption Methods
Let’s start by defining some terms. There are four primary ways to encrypt your data while it is at rest:
OS-Level and Filesystem Encryption
Operating system or disk-level encryption protects entire file systems or disks. This method is application-agnostic and offers encryption with minimal overhead. Think technologies like luks in Linux or FileVault in MacOS.
Pros:
- Transparent to applications and the database
- Simplifies management by applying encryption to the entire storage layer
- Offloads encryption and decryption processing to the OS
- Minimal performance and operational impact
- Widely understood and implemented technology
Cons:
- Less granular control over specific databases or tables
- Backups are not encrypted by default
- Additional overhead is required to ensure encryption keys are properly managed
Storage Device Encryption
Encryption is directly implemented on storage devices such as hard disk drives or SSDs which automatically encrypt all of the data written to their storage.
Pros:
- Suitable for environments with hardware security requirements
- Minimal performance and operational impact
- Offloads encryption and decryption processing to the hardware layer
Cons:
- Less granular control over specific databases or tables
- Additional overhead is required to ensure encryption keys are properly managed
Transparent Disk Enc
[...]Protecting Personally Identifiable Information in PostgreSQL: A Critical Requirement for Financial Organizations
Posted by Umair Shahid in Stormatics on 2024-05-29 at 16:15
Protect personally identifiable information (PII) in PostgreSQL databases, a critical requirement for financial organizations.
The post Protecting Personally Identifiable Information in PostgreSQL: A Critical Requirement for Financial Organizations appeared first on Stormatics.
Helping PostgreSQL® professionals with AI-assisted performance recommendations
Posted by Francesco Tisiot in Aiven on 2024-05-28 at 15:00
Since the beginning of my journey into the data world I've been keen on making professionals better at their data job. In the previous years that took the shape of creating materials in several different forms that could help people understand, use, and avoid mistakes on their data tool of choice. But now there's much more into it: a trusted AI solution to help data professional in their day to day optimization job.
From content to tooling
The big advantage of the content creation approach is the 1-N effect: the material, once created and updated, can serve a multitude of people interested in the same technology or facing the same problem. You write an article once, and it gets found and adopted by a vast amount of professionals.
The limit of content tho, it's that it is an extra resource, that people need to find and read elsewhere. While this is useful, it forces a context switch, moving people away from the problem they are facing. Here is where tooling helps, providing assistance in the same IDE that professionals are using for their day to day work.
Tooling for database professionals
I have the luxury of working for Aiven which provides professionals an integrated platform for all their data needs. In the last three years I witnessed the growth of the platform and its evolution with the clear objective to make it better usable at scale. Tooling like integrations, Terraform providers and the Console facilitate the work that platform administrators have to perform on daily basis.
But what about the day to day work of developers and CloudOps teams? This was facilitated when dealing with administrative tasks like backups, creation of read only replicas or upgrades, but the day to day work of optimizing the workloads was still completely on their hands.
Using trusted AI to optimize database workloads
This, however, is now changing. With the recent launch of Aiven AI Database Optimizer we are able to help both developer and CloudOps in their day to day optimization work!
Aive
[...]Introducing Aiven's AI Database Optimizer: The First Built-In SQL Optimizer for Enhanced Performance
Posted by Francesco Tisiot in Aiven on 2024-05-28 at 12:00

An efficient data infrastructure is a vital component in building & operating scalable and performant applications that are widely adopted, satisfy customers, and ultimately, drive business growth. Unfortunately, the speed of new feature delivery coupled with a lack of database optimization knowledge is exposing organizations to high risk performance issues. The new Aiven AI Database Optimizer helps organizations address performance both in the development and production phase, making it simple to quickly deploy, fully optimized, scalable, and cost efficient applications.
Fully integrated with Aiven for PostgreSQL®, Aiven AI Database Optimizer offers AI-driven performance insights, index, and SQL rewrite suggestions to maximize database performance, minimize costs, and make the best out of your cloud investment.
How does AI Database Optimizer work?
Aiven AI Database Optimizer is a non-intrusive solution powered by EverSQL by Aiven that gathers information about database workloads, metadata and supporting data structures, such as indexes. Information about the number of query executions and average query times are continually processed by a mix of heuristic and AI models to determine which SQL statements can be further optimized. AI Database Optimizer then delivers accurate, secure optimization suggestions that you can trust, and that can be adopted to speed up query performance.
Recommendations from Aiven’s AI Database Optimizer are already trusted by over 120,000 users in organizations ranging from startups to the largest global enterprises, who have optimized more than 2 million queries to date.
How does AI Database Optimizer help organizations?
During development, AI Database Optimizer enables early performance testing, allowing easier redesign or refactoring of queries before they impact production. This enables customers to foster a culture of considering performance from the get-go, ensuring it is a priority throughout development rather than an afterthought.
AI Database
[...]Why do I have a slow COMMIT in PostgreSQL?
Posted by Laurenz Albe in Cybertec on 2024-05-28 at 05:42

Sometimes one of our customers looks at the most time consuming statements in a database (either with pg_stat_statements or with pgBadger) and finds COMMIT in the high ranks. Normally, COMMIT is a very fast statement in PostgreSQL, so that is worth investigating. In this article, I will explore the possible reasons for a slow COMMIT and discuss what you can do about it.
The basic COMMIT activity in PostgreSQL
A slow COMMIT is a surprising observation, because committing a transaction is a very simple activity in PostgreSQL. In most cases, all a COMMIT has to do is
- set the two bits for the transaction in the commit log to
TRANSACTION_STATUS_COMMITTED(0b01) (persisted inpg_xact) - if
track_commit_timestampis set toon, record the commit timestamp (persisted inpg_commit_ts) - flush the write-ahead log (WAL) (persisted in
pg_wal) to disk, unlesssynchronous_commitis set tooff
Note that because of the multi-versioning architecture of PostgreSQL, both COMMIT and ROLLBACK are normally very fast operations: they both don't have to touch the tables, they only register the status of the transaction in the commit log.
The most frequent reason for slow COMMIT: disk problems
From the above it is clear that a potential cause of slowness is disk I/O. After all, flushing the WAL to disk causes I/O requests. So the first thing you should check is if the disk has a problem or is under load:
- On Linux, you can use commands like “
vmstat 1” or “sar -p 1” to measure the percentage of CPU time spent waiting for I/O (“wa” invmstatand “%iowait” insar). If that value is consistently above 10, you can be pretty certain that the I/O system is under stress. - With NAS, you should check if the TCP network is overloaded.
- If the storage is a shared SAN or NAS, the disks may be shared wth other machines, and you should check if there is contention on the storage system.
- Failing disks, other hardware problems or operating system problems can lead to in
An assistant to copy data from a remote server
Posted by Florent Jardin in Dalibo on 2024-05-28 at 00:00
During the last PGSession organized by Dalibo, I wrote and led a workshop (french) on the migration to PostgreSQL using Foreign Data Wrappers, or FDW. This was an opportunity to present to the general public the db_migrator extension for which I wrote an article on this blog.
While working on this workshop, we noticed that copying data with the db_migrator extension is not perfectly supported. Indeed, although there is a low-level function to distribute the transfer table by table over several processes, many situations will require writing a large number of SQL queries to get out of trouble. Over the following months, I worked on the design of an assistant written in PL/pgSQL whose purpose is to simplify the generation of these queries.
Code Conversion Chronicles – Trigger Order of processing in Oracle to PostgreSQL Migration.
Posted by Deepak Mahto on 2024-05-27 at 17:02
Database triggers allow encapsulation of multiple functionalities that are automatically invoked on specific events or DML operations like INSERT, UPDATE, or DELETE. The invocation of triggers can be controlled as BEFORE or AFTER the triggering events, either for each change or per statement. In migrating from Oracle to PostgreSQL, it is important to be aware of triggers conversion gotchas.
In this blog, we discuss the default order of processing when multiple triggers are defined on the same table for the same events with the same characteristics. We will explore how this works in Oracle, how to alter the order, and how it operates in PostgreSQL.
Oracle – Trigger Order of Execution
We are defining a sample Oracle table that prints a message to understand the default order of processing.
--Tested on Oracle 19c
create table trigger_sample
(
col1 integer
);
CREATE OR REPLACE TRIGGER trigger0
BEFORE INSERT OR UPDATE OR DELETE ON trigger_sample
FOR EACH ROW
follows trigger1
BEGIN
DBMS_OUTPUT.PUT_LINE('RUNNING - trigger0 ');
END;
/
CREATE OR REPLACE TRIGGER trigger1
BEFORE INSERT OR UPDATE OR DELETE ON trigger_sample
FOR EACH ROW
BEGIN
DBMS_OUTPUT.PUT_LINE('RUNNING - trigger1 ');
END;
/

By default, Oracle follows the order of trigger creation time and invokes triggers on similar events based on this order of creation time.
In Oracle, we can also influence the order by using the FOLLOWS clause to define which existing trigger to follow as part of the execution order. In our sample, we will alter trigger0 to follow trigger1.
CREATE OR REPLACE TRIGGER trigger0
BEFORE INSERT OR UPDATE OR DELETE ON trigger_sample
FOR EACH ROW
follows trigger1
BEGIN
DBMS_OUTPUT.PUT_LINE('RUNNING - trigger0 ');
END;
/

PostgreSQL – Trigger Order of Execution
Migration offers ample opportunities to gain a deeper understanding of both the source and target databases. It’s not uncommon to encounter similar triggering events on the same tables, as functionalities often span acro
[...]Custom PostgreSQL extensions with Rust
Posted by Radim Marek on 2024-05-24 at 00:00
This article explores the pgrx framework, which simplifies the creation of custom PostgreSQL extensions to bring more logic closer to your database. Traditionally, writing such extensions required familiarity with C and a deep understanding of PostgreSQL internals, which could be quite challenging. pgrx lowers the barrier and allows developers to use Rust, known for its safety and performance, making the process of creating efficient and safe database extensions much more accessible.
pg_sysload#
When working with large datasets and migrations (as discussed in How Not to Change PostgreSQL Column Type), or during resource-intensive maintenance tasks, you'll want to optimise speed and minimise disruption to other processes. One way to control the pace of batch operations is to consider the load on the underlying system.
Many Unix-based systems (we will focus on Linux) provide a valuable metric called the system load average. This average consists of three values: the 1-minute, 5-minute, and 15-minute load averages. The load average is not normalised for the number of CPU cores, so a load average of 1 on a single-core system means full utilisation, while on a quad-core system, it indicates 25% utilisation.
In many cases, the system load average is also an excellent indicator of how ongoing operations are impacting a busy database cluster. In this article, we will create a PostgreSQL extension with a function called sys_loadavg() that retrieves this load information. We will use the /proc/loadavg file (part of the proc filesystem), which exposes underlying system details.
Getting Started with pgrx#
Before we start, ensure you have:
- Rust installed (Get Started with Rust)
-
System dependencies installed for
pgrx
With these prerequisites in place, you can install pgrx itself and create a new extension skeleton:
cargo install --locked cargo-pgrx
cargo pgrx new pg_sysload
cd pg_sysload
This gives you a complete environment for developing your own PostgreSQL extensions in R
[...]Top posters
Number of posts in the past two months
 David Wheeler (Tembo) - 10
David Wheeler (Tembo) - 10- Deepak Mahto - 8
- Radim Marek - 7
- Hubert 'depesz' Lubaczewski - 5
- Henrietta Dombrovskaya - 5
- Peter Eisentraut (EDB) - 5
- semab tariq (Stormatics) - 5
- Luca Ferrari - 4
- Ashutosh Bapat - 4
- Gabriele Bartolini (EDB) - 4
Top teams
Number of posts in the past two months
- Tembo - 17
- EDB - 13
- Stormatics - 11
- Cybertec - 6
- Crunchy Data - 5
- Highgo Software - 4
- Percona - 4
- Data Egret - 3
- CitusData - 2
- Supabase - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.