For all you top.hatnote.com readers out there, we just added some shortcuts to do a web search (🔍) and news search (🗞️) for each article. Hope this saves you a click or two!
{{Hatnote}}
Anonymous asked:
Hello. Thank you for Hatnote. I love having it in the background while I work. I was wondering whether there are any issues (legal, copyright, etc.) in using the Hatnote audio for music creation. For example, could I use snippets of the audio in a song I create? Are there permissions or attributions needed? Thanks!
Hi! Glad you enjoy Listen to Wikipedia. Feel free to create and remix; attribution and a CC license would be much appreciated. Happy listening and creating!
{{Hatnote}}
Anonymous asked: Are there any time-lapse videos of the rcmap of English Wikipedia editing over 24 hours to show how the editing activity shifs around the globe?
Not that we know of! Would love to see one, could make a great addition to seealso.org :)
Just a quick update to this post: we made some minor changes and now there’s a button to unmute the first time you visit listen.hatnote.com. If you can see the activity, but can’t hear the chimes, check your volume levels and click on it (or anywhere), to get back to your regularly schedule program :)
{{Hatnote}}
Anonymous asked: The first time I went to "listen to Wikipedia" from a browser (Chrome) I was delighted. But now I get no sound. There is a control on the upper-right of the page that looks like a volume slider -- but moving it around has no effect. My speakers are working fine, and I haven't changed anything on my computer (that I know of) since I did get sound that first time. I have done a Windows update, but IIRC the sound stopped working before I did that. Do I need to configure something? Thanks.
Hey listener! Sorry to hear about the trouble, but yes, we can confirm that it’s not just you.
Due to new Chrome policy changes, the browser automutes listen.hatnote.com. We’re going to need to make some code changes to fix that. We’ll need to start in a muted state and then have users click unmute, at least for Chrome users.
No exact date on when we’ll have that fix out, but Stephen and I should have some spare time in the next few weeks, I’m sure. In the meantime might I recommend switching to Firefox. Besides not having made this policy change, Firefox is just a better browser from a much better company, and Hatnote’s browser of choice! :)
– Mahmoud
PS If you, or anyone reading this happens to have a bit of time and skill to fix this, we are always open to contributions!
Unlocking the human potential of Wikidata
Wikidata is amazing. Thanks to the amazing Wikidata evangelists out
there, I feel confident that, given at least five minutes, I can
convince anyone that Wikidata offers a critical service necessary for
Wikipedia, other wiki projects, and generally the future of knowledge. Challengers welcome. :)
But Wikidata has a problem. Right now it’s optimized to ingest and grow. We’ve written about how it’s not ideal for maintenance of the datasets, but automated ingestion of datasets is what Wikidata does best.
All this automated growth doesn’t necessarily connect well with the organic growth of Wikipedia and other projects. And we can see that Wikidata hasn’t truly captured the positive attentions of existing editor communities.
For that human touch Wikidata needs ever so much, it must reach out to the projects that gave rise to it.
One idea for doing this would be to make human editing of Wikidata
easier. Make editing Wikidata as easy as adding a citation to
Wikipedia. Literally.
Highlight a statement, click a button like “Structure this statement” and grow Wikidata, all without leaving your home wiki.
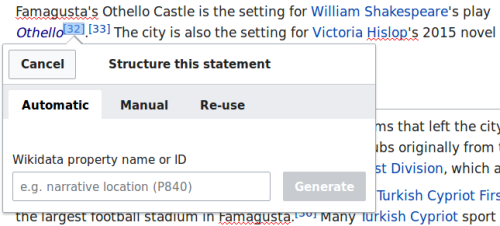
What it might look like to edit Wikidata from Wikipedia.
While Wikitext will always have its place for me, I’ve quite warmed up to the visual editor, and prefer its interface for adding citations. While it’s only an idea for an experiment at the moment, how might an inline Wikidata editor following the same pattern could be change the game for Wikidata?
A lot of data is already citing back to home wikis, but a powerful enough editor could pull the citation on a statement through to the Wikidata entry, along with the import source.
So much data is already coming from Wikipedia, but humans can do even better.
I have always thought it would be great to see Wikidata’s support for multi-valued properties leveraged more fully. A language-agnostic knowledgebase will be a new space to compare and resolve facts. A meeting of the many minds across different languages of Wikipedia could spell better information for all.
An advanced enough system could encourage contributions on the basis of coverage, highlighting cited statements which have not yet been structured.
And of course, at the very least, we speed up building an intermediary representation of knowledge, not tied to a specific language. People sharing knowledge across wikis, helping to further bootstrap a Wikidata community with close ties to its older siblings.
Wikicite 2017, and the 7 features Wikidata needs most
At Wikicite 2017, discussions revolved around an ambitious goal to use Wikidata to create a central citation database for all the references on Wikipedia. Citations are the essential building blocks of verifiability, a core tenet of Wikipedia. This project aims to give citations the first-class treatment they deserve.
We saw three important questions emerge at the conference:
- What does a good citation database look like?
- How can we build this on Wikidata?
- How can we integrate this with Wikipedia?
These are hard questions. To answer them, Wikicite brought together:
- Expert ontologists and librarians specializing in citation and reference modeling
- Groups like Crossref with treasure troves of rich bibliographic data.
- Developers and data scientists with experience importing datasets into Wikidata.

Wikicite may be young, but clear progress has been made already. Wikidata now boasts some great collections of bibliographic data, like the Zika corpus and data from the genewiki project. Some Wikipedias, like French and Russian, are experimenting with generating citations using Wikidata. Some citation databases are integrated with Visual Editor to make it easy to add rich citations on Wikipedia–which can hopefully one day be added to Wikidata for further reuse and tracking.
There are still a few features that Wikidata needs to be a first-class host for citation data. Even the best structured data takes time to define in Wikidata’s precise terms of items, properties, modifiers, and qualifications. Although it’s possible to use some handy tools on Wikidata for bulk actions, it often requires changing your dataset to match the tool’s specific format, or writing bespoke code for your dataset. It’s still challenging to ensure data is high quality, well-sourced, and ready for long-term maintenance.

In listening to researchers’ talks, discussing with experts in working groups, and workshopping code with some of Wikidata’s soon-to-be biggest users, we determined that Wikidata needs seven features for true Wikicite readiness:
- Bulk data import. There must be an easy process for loading large amounts of data onto Wikidata. There are a few partial tools, like QuickStatements,
which, while itself aptly-named, is just one part of an often-arduous
workflow. Other people have written custom bots to import their specific
dataset, on top of libraries like Wikidata Integrator or pywikibot. Without help from an experienced Wikidata contributor, there is not an easy self-service way to move data in bulk.
- Sets. Wikidata needs a feature to track and curate specific groups of items. Sets are a necessary concept to answer questions about a complete group. Right now, you can use Wikidata to tell you facts about the states in Austria, but it cannot tell you the complete list of all states in Austria. Sets are key for curators to perform this sort of cross-sectional data management.
- Data management tools.
Data curators need tools to monitor data of interest. Wikidata is big.
The basic tools like watchlists were designed for Wikipedians articles
on a much smaller scale, with a much coarser granularity than the
Wikidata statement or qualifier. An institution that donates data to
Wikidata may want to monitor thousands (maybe hundreds of thousands) of
items and properties. Donors of complete datasets will want to watch
their data for deletions, additions, and edits.
- Grouping edit events.
At the moment, many community members are adding data to Wikidata in
bulk, but this is a fact that Wikidata’s user interface struggle to
represent. Wikidata currently offers a piecemeal history of user’s
individual edits, and encourages editors to add citations and references
for individual statements. These features are vital, but we need a
higher-level grouping feature for higher-level data uploads. For
instance, it would be helpful to have an “upload ID” for associated
edits across many claims. It would also be useful to have a dedicated
namespace for human- and machine-readable documentation of the data load
process, a kind of README that addresses the whole action. This kind of
documentation not only helps community members get answers to questions
before, during, and after large-scale activity, but it also helps
future data donors learn about and follow best practices.
- A draft or staging space.
There should be a way for people to add content to Wikidata without
directly modifying “live” data. Currently, when something is added to
Wikidata it is immediately mixed in with everything else. It’s daunting
for new users to have to get it right on the first try, let alone take
quick corrective action in the face of inevitable mistakes. Modeling a
dataset in Wikidata’s terms requires using Wikidata’s specific
collection of items and properties. You may not see how your data fits
into Wikidata—perhaps requiring new properties and items—until you begin
to add it. Experienced Wikidata volunteers may review data to ensure
it’s high quality, but it would be better to enable this collaborative
process before data is part of the project’s official collection. You
should be able to upload your data to a staging space on Wikidata,
ensure it’s high quality and properly structured, and then publish it
when it’s ready. The PrimarySources tool is
a community-driven start to this, but such a vital feature needs
support from the core. In the longer term, this feature is a small step
toward maximizing Wikidata consistency, by setting the stage to
transactionally add and modify large-scale data. It would be helpful to have data cleanup tools, similar to OpenRefine, available for data staging.
- Data models.
Wikidata needs new ways to collaborate on new kinds of items.
Specifically, we need a better way to reach consensus on models for
certain standard types of data. Currently, it’s possible describe the
same entity in multiple ways, and lacking a forum for this process, it’s
hard to discuss the differences. See, for instance, the drastically
different ways that various subway lines are
described as Wikidata items. Additionally, some models may want to
impose certain constraints on instances, or at least indicate if an item
complies with its model. Looking to the future, tools for collaborative
data modeling would grow to include a library of data models unlike any
other.
- Point in time links. There should be a way to share a dataset from Wikidata at a given point in time. Wikidata, like Wikipedia, is continuously changing. Wikipedia supports linking to a specific revision of an article at a point in time using a permalink, and you can do the same for a specific Wikidata item. However, Wikidata places special emphasis on relationships between items, yet does not extend the permalink feature to these relationships. If you run a query on the Wikidata Query Service (the SPARQL endpoint for Wikidata), and then share the query with someone else, they may see different results.
These seven features came up consistently across several groups and discussions at Wikicite. As a room full of problem solvers, several good projects are already underway to provide community-based solutions in these areas. Among the handful that were started at the conference, we are pleased to share we’ve started work on Handcart, a tool for simplifying medium-sized bulk imports, for citation data, and much, much more. We believe trying to fix a problem is the best way to learn its details and nuances.
Wikicite made a strong case that Wikidata has a lot of valuable potential for citations, and citations are crucial for Wikipedia. As we work to address these missing features in Wikidata, we are happy to be part of the Wikicite movement to build a more verifiable world.

Thanks for inviting us, Wikicite, hope to see everyone again next time!
Wikicite 2017

Having a great pre-WikiCite gelato social here in Vienna. Also, say hi to the newest Hatnote contributor, Pawel. He does the frontend for Montage and also does great work on Monumental. As you can see, we’re all pretty excited for what Wikicite 2017 will bring (and also ice cream).
Montage and Wiki Loves Monuments 2016
Hatnote welcomed the holidays this year even more than usual, as they coincided with a fine end to another successful chapter of Wikipedia-related work. We’ve got several projects to talk about, but the centerpiece this year is Montage.

Montage is a judging tool used to judge well over a hundred thousand of the submissions to this year’s Wiki Loves Monuments photography competition.
We wrote more about it over on the Wikimedia blog, take a look!
In the meantime, happy holidays from Stephen, Pawel, me, and the rest of the Hatnote crew!

Hopefully next year we’ll all be able to make it into the holiday photo!
Hashtags, One Year In
It’s been around one year since Hatnote announced hashtags on Wikipedia. The Wikimedia Blog has a full story on several of the impacts and inroads being made by supporting this powerful convention on Wikipedia.
Follow that link or if you’re in a hurry, check out the new Wikipedia Social Search interface directly!
Announcing the Hatnote Top 100
Moreso than any other major site, Wikipedia is centered around knowledge, always growing, and brimming with information. It’s important to remember that the insight of our favorite community-run encyclopedia often follows the focus of its massive readership. Here at Hatnote, we’ve often wondered, what great new topics is the community learning about now?
To shed more light on Wikipedia’s reading habits, we’re pleased to announce the newest addition to the Hatnote family: The Hatnote Top 100, available at top.hatnote.com. Because we can’t pass up a good headwear-based pun.
Updated daily, the Top 100 is a chart of the most-visited articles on Wikipedia. Unlike the edit-oriented Listen to Wikipedia and Weeklypedia, Top 100 focuses on the biggest group of Wikipedia users: the readers. Nearly 20 billion times per month, around 500 million people read articles in over 200 languages. Top 100’s daily statistics offer a window into where Wikipedia readers are focusing their attention. It also makes for a great way to discover great chapters of Wikipedia one wouldn’t normally read or edit.

Clear rankings, day-to-day differences, social media integration, permalinks, and other familiar simple-but-critical features were designed to make popular Wikipedia articles as relatable as albums on a pop music chart. In practice, popular news stories and celebrities definitely make the Top 100, but it is satisfying to see interesting corners of history and other educational topic sharing, if not dominating, the spotlight.
In addition to a clear and readable report, Top 100 is also a machine-readable archive, with reports dating back to November 2015, including JSON versions of the metrics, as well as RSS feeds for all supported languages and projects. It’s all available in over a dozen languages (and we take requests for more). The data comes from a variety of sources, most direct from Wikimedia, including a new pageview statistics API endpoint that we’ve been proud to pilot and continue to use. And yes, as with all our projects the code is open-source, too.
For those of you looking to dig deeper than Wikipedia chart toppers, there are several other activity-based projects worth mentioning:
- stats.grok.se - The original, venerable pageview grapher and API
- Wikimedia Report Card - Advanced metrics and data used by the Wikimedia Foundation
- The Open Wikipedia Ranking - Traffic stats and more
- @WikipediaTrends - A bot posting notable upward traffic spikes
- The Top 25 Report - A manually-compiled weekly report of views and likely reasons
- The Weeklypedia - Weekly edit statistics, emailed and archived by Hatnote
And there are other visualizations on seealso.org as well. But for those who like to keep it simple, hit up the Hatnote Top 100, subscribe to a feed, and/or follow us on Twitter. See you there!
P.S. The Wikimedia Blog featured us in the actual announcement for the PageViews API. Yay!
Longtime Hatnote fans probably know, while Listen to Wikipedia is always broadcasting, things can get pretty quiet on the Hatnote blog. It’s been over a month since our last post!
Well today Hatnote breaks that radio silence. Literally.
This morning, Silicon Valley’s public radio station, KQED, broadcast a story about Hatnote through all of the Bay Area and northern California. Read the full story here.
A big thank you to Sam Harnett, who produced the story. You should follow his 90-second podcast, The World According to Sound, which also featured a Wikipedia episode just last week. You can probably guess which sounds they used :)
And that’s not all, we have a lot more planned before the year is out, so stay tuned!
(Source: SoundCloud / KQED)
De Venezuela a Gran Hermano: los artículos más editados de Wikipedia en español

De Venezuela a Gran Hermano: los artículos más editados de Wikipedia en español. Noticias de Tecnología. 142 de los 500 artículos más revisados de Wikipedia en lengua española están relacionados con el fútbol. La geografía es la siguiente gran categoría en número de edición de artículos. ...
We recently helped El Confidencial get statistics about the most edited articles on Spanish Wikipedia. You can see a few clusters of popular topics, such as countries, sports teams, and TV shows. You can also compare the data with the most edited topics on English Wikipedia.
If you want weekly updates on the most edited Wikipedia articles, don’t forget to sign up for Weeklypedia!