Review: Scikit-learn shines for simpler machine learning
Well-tended Python framework offers wide selection of robust algorithms, but no deep learning






Contributor, InfoWorld |

-
Scikit-learn 0.20.3
Scikits are Python-based scientific toolboxes built around SciPy, the Python library for scientific computing. Scikit-learn is an open source project focused on machine learning: classification, regression, clustering, dimensionality reduction, model selection, and preprocessing. It’s a fairly conservative project that’s pretty careful about avoiding scope creep and jumping on unproven algorithms, for reasons of maintainability and limited developer resources. On the other hand, it has quite a nice selection of solid algorithms, and it uses Cython (the Python-to-C compiler) for functions that need to be fast, such as inner loops.
Among the areas Scikit-learn does not cover are deep learning, reinforcement learning, graphical models, and sequence prediction. It is defined as being in and for Python, so it doesn’t have APIs for other languages. Scikit-learn doesn’t support PyPy, the fast just-in-time compiling Python implementation because its dependencies NumPy and SciPy don’t fully support PyPy.
Scikit-learn doesn’t support GPU acceleration for multiple reasons having to do with the complexity and the machine dependencies it would introduce. Then again, aside from neural networks, Scikit-learn has little need for GPU acceleration.
Scikit-learn features
As I mentioned, Scikit-learn has a good selection of algorithms for classification, regression, clustering, dimensionality reduction, model selection, and preprocessing. In the classification area, which is about identifying the category to which an object belongs, and is called supervised learning, it implements support vector machines (SVM), nearest neighbors, logistic regression, random forest, decision trees, and so on, up to a multilevel perceptron (MLP) neural network.
However, Scikit-learn’s implementation of MLP is expressly not intended for large-scale applications. For large-scale, GPU-based implementations and for deep learning, look to the many related projects of Scikit-learn, which include Python-friendly deep neural network frameworks such as Keras and Theano.
For regression, which is about predicting a continuous-valued attribute associated with an object (such as the price of a stock), Scikit-learn has support vector regression (SVR), ridge regression, Lasso, Elastic Net, least angle regression (LARS), Bayesian regression, various kinds of robust regression, and so on. That’s actually a bigger selection of regression algorithms than most analysts might want, but there are good use cases for each one that has been included.
For clustering, an unsupervised learning technique in which similar objects are automatically grouped into sets, Scikit-learn has k-means, spectral clustering, mean-shift, hierarchical clustering, DBSCAN, and some other algorithms. Again, the gamut of conservative algorithms has been included.
Dimensionality reduction is about decreasing the number of random variables to consider, using decomposition techniques such as principal component analysis (PCA) and non-negative matrix factorization (NMF), or feature-selection techniques. Model selection is about comparing, validating, and choosing parameters and models, and it uses algorithms such as grid search, cross-validation, and metric functions. For both areas, Scikit-learn includes all of the well-proven algorithms and methods, in easily accessible APIs.
Preprocessing, which involves feature extraction and normalization, is one of the first and most important parts of the machine learning process. Normalization transforms features into new variables, often with zero mean and unit variance, but sometimes to lie between a given minimum and maximum value, often 0 and 1. Feature extraction turns text or images into numbers usable for machine learning. Here again, Scikit-learn serves up all of the tasty classic dishes you would expect at this smorgasbord. You are free to collect whichever ones appeal to you.
Note that feature extraction is quite different from feature selection, mentioned earlier under dimensionality reduction. Feature selection is a way of improving learning by removing nonvarying, covariant, or otherwise statistically unimportant features.
In short, Scikit-learn includes a full set of algorithms and methods for dimensionality reduction, model selection, feature extraction, and normalization, although it lacks any kind of guided workflow for accomplishing these other than a good collection of examples and good documentation.
Installing and running Scikit-learn
My installation of Scikit-learn may well have been my easiest machine learning framework installation ever. Since I already had all of the prerequisites installed and sufficiently up-to-date (Python, Numpy, and Scipy), it took one command:
$ sudo pip install -U scikit-learn
OK, it took me two commands, because the first time I forgot sudo.
That got me Scikit-learn 0.18.1. For good measure, I also checked out the GitHub repository, installed the nose testing framework, and built the development version of Scikit-learn from source, which was as simple as changing to the root of the repository and typing make. It took a while to compile the Python, generate and compile all the C files, link the assembly, and run all the tests, but didn’t require any intervention.
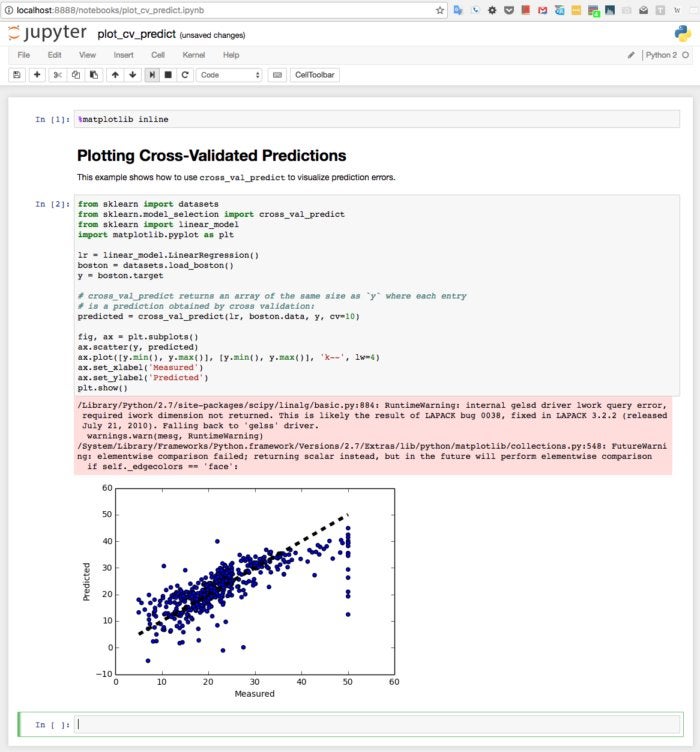
Running my first Scikit-learn example was also very easy. From the general examples page, I clicked into the example for plotting cross-validated predictions, read through the notebook, downloaded the Python source code and Jupyter notebook, and ran them. The Python source chugged along for a few seconds, generated some warning messages, and popped up a graph. The Jupyter notebook did essentially the same thing when I ran it interactively, as you can see in the figure below.
 InfoWorld
InfoWorld
Jupyter notebook running on a MacBook Pro displaying the Scikit-learn tutorial about using cross_val_predict to visualize prediction errors. The first error message appears to be caused by a bug in Apple’s vecLib framework, a CPU-optimized but old version of the Atlas implementation of LAPACK and BLAS.
Scikit-learn earns the highest marks for ease of development among all the machine learning frameworks I’ve tested, mostly because the algorithms work as advertised and documented, the APIs are consistent and well-designed, and there are few “impedance mismatches” between data structures. It’s a pleasure to work with a library in which features have been thoroughly fleshed out and bugs thoroughly flushed out.
Learning Scikit-learn
The Scikit-learn documentation is good, and the examples are many — about 200 in total. Most examples include at least one graph produced from the analyzed data using Matplotlib. These all contribute to the library’s ease of development and its ease of learning.
There is one long tutorial, "A tutorial on statistical-learning for scientific data processing," that has five sections and an appendix about finding help. The tutorial is pretty good, both at covering the basic concepts and showing examples using actual data, code, and graphs. It also calls out examples related to the text — for instance, the comparison of four different SVM classifiers shown in the figure below.
 InfoWorld
InfoWorld
Four support vector machine (SVM) classifiers compared graphically, an example to accompany the main Scikit-learn tutorial. The graphics are easy to visualize because the Iris classification data set is low-dimensional to begin with and we’re looking at only two of the four features. The data set also has a relatively small number of points. ("RBF" stands for "radial basis function.")
The examples I worked through were all fairly clear on their web pages. In many cases, when I downloaded and ran the examples, they would throw warnings not shown on the web page, but would always produce the same results. The first figure above, showing my Jupyter notebook output for plotting cross-validated predictions, is a good example.
I attribute most of the warnings to defects in the Apple vecLib framework and evolution in the Python libraries. Some seem to be warnings in Python 2.7.10 that weren’t present in whatever version was used for the web page. The figure below has such a warning; the corresponding web page does not.
 InfoWorld
InfoWorld
This example uses Scikit-learn’s small handwritten digit data set to demonstrate semi-supervised learning using a Label Spreading model. Only 30 of the 1,797 total samples were labeled. The Python warning in the middle of the notebook shown above is not present in the corresponding web page.
As a Python library for machine learning, with deliberately limited scope, Scikit-learn is very good. It has a wide assortment of well-established algorithms, with integrated graphics. It’s relatively easy to install, learn, and use, and it has good examples and tutorials.
On the other hand, Scikit-learn does not cover deep learning or reinforcement learning, which leaves out the current hard but important problems, such as accurate image classification and reliable real-time language parsing and translation. In addition, it doesn't include graphical models or sequence prediction, it can’t really be used from languages other than Python, and it doesn't support PyPy or GPUs.
On the gripping claw, the performance Scikit-learn achieves for machine learning other than neural networks is pretty good, even without the acceleration of PyPy or GPUs. Python is often zippier than people expect from an interpreter, and the use of Cython to generate C code for inner loops eliminates most of the bottlenecks in Scikit-learn.
Clearly, if you’re interested in deep learning, you should look elsewhere. Nevertheless, there are many problems — ranging from building a prediction function linking different observations to classifying observations to learning the structure in an unlabeled data set — that lend themselves to plain old machine learning without needing dozens of layers of neurons, and for those areas Scikit-learn is very good.
If you’re a Python fan, Scikit-learn may well be the best option among the plain machine learning libraries. If you prefer Scala, then Spark ML might be a better choice. And if you like designing your learning pipelines by drawing diagrams and writing an occasional snippet of Python or R, then the Microsoft Cortana Analytics Suite — specifically the Azure Machine Learning Studio — might fit your preferences nicely.
---
Cost: Free open source. Platform: Requires Python, NumPy, SciPy, and Matplotlib. Releases are available for MacOS, Linux, and Windows.
| InfoWorld Scorecard |
Models and algorithms (25%)
|
Ease of development (25%)
|
Documentation (20%)
|
Performance (20%)
|
Ease of deployment (10%)
|
Overall Score (100%)
|
|---|---|---|---|---|---|---|
| Scikit-learn 0.18.1 | 9 | 9 | 9 | 8 | 9 |
Copyright © 2017 IDG Communications, Inc.