
On Thursday, another National Security Agency document from the trove obtained by former NSA contractor Edward Snowden was published by The Guardian. The new slides from the NSA’s top-secret WebWorld intranet are from a presentation called “Content Extraction Enhancements for Target Analytics: SMS Text Messages: A Goldmine to Exploit.” Aside from the overuse of colons, the slides include details of a program that collects massive amounts of data from the world’s cellular phone networks.
The slides were published just after security expert Bruce Schneier met with a group of members of Congress to discuss what was revealed by the Snowden documents about the NSA. The meeting, ironically, could not be held in a secure facility to go over information in documents not yet published—because Schneier doesn’t have clearance.
According to the June 2011 slides, the NSA collects 194 million messages a day—not just SMS messages, but system-generated messages as well: geolocation data, synchronizing address book data (vCards), missed call messages, call roaming data, and other data as well. This trove is collected in Dishfire, an SMS repository system that is much like the XKeyscore Internet monitoring system. Like XKeyscore, Dishfire captures large volumes of “untargeted” data—messages that aren’t associated with individuals identified for surveillance—based on some basic filtering out to “minimize” data such as messages from US numbers.
A program called "Prefer" allows analysts to query the repository of data based on metadata within Dishfire. That metadata, like the XKeyscore Internet data, can also include keywords and data structures out of SMS data, such as travel information and financial transactions. Unlike with XKeyscore, since SMS messages are relatively small bits of data, the “metadata” created by collecting mobile phone information can contain a much larger percentage of the original content. That means that there is much more identifying data in the “unselected” data within Dishfire—allowing analysts to go hunting through the content of millions of people each day that have no relation to ongoing surveillance operations.
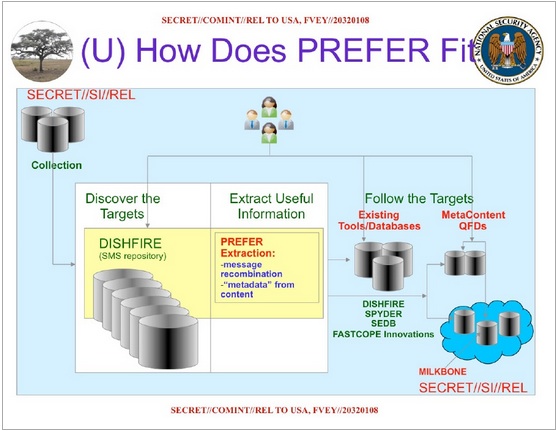
Prefer has been in operation since January 2008, feeding content from the SMS repository into NSA search engines and other analytical databases. Some of this data can be pulled out in near real time to track targets that the NSA has already identified, but it can also be used to identify new targets by searching through connections and processing metadata about the content of text messages—keywords, phrases, or combinations of factors that match a profile of interest to the NSA.
Each day, the NSA uses Prefer to pull out metadata that includes more than 110,000 names and contact data from vCards, 1.6 million border crossings based on roaming data, over 5 million missed call alerts that can be used to “chain” contacts, and over 800,000 financial transactions. It also extracts 76,000 pieces of geolocation data each day, including requests for meetings, addresses, and directions.
While the NSA has screened most US SMS traffic out of the Dishfire repository, its UK counterparts aren’t above using data collected by the NSA on its own citizens. The British intelligence agency GCHQ has used data collected by the NSA to search the metadata of “untargeted and unwarranted” users within Britain to bypass legal constraints on their own surveillance.
reader comments
103