Review: HPE’s machine learning cloud overpromises, underdelivers
Haven OnDemand’s enterprise search and format conversions are the strongest services, while more interesting capabilities are not fully cooked






Contributor, InfoWorld |
-
Hewlett Packard Enterprise Haven OnDemand
Machine learning reviews
- Review: 6 machine learning clouds
- Review: Azure Machine Learning is for...
- Review: Amazon puts machine learning in...
- Review: Databricks makes big data...
- Review: IBM Watson strikes again
Developers longing to build more intelligent, more proactive, more personalized apps seem to gain more options with every passing day. With Haven OnDemand, Hewlett-Packard Enterprise (HPE) has joined the applied machine learning fray, competing directly with IBM Watson Services, Microsoft Cortana Analytics Suite, and several Google ML-based APIs.
Haven OnDemand is a platform for building cognitive computing solutions using text analysis, speech recognition, image analysis, indexing, and search APIs. While IBM based its cognitive computing/machine learning cloud services primarily on Watson, the “Jeopardy” winner, HPE based its recently announced Haven OnDemand services primarily on IDOL, its enterprise search engine.
This lineage shows in the Haven OnDemand selection of services: for example, the wide variety of connectors and file formats already supported, the emphasis on extracting information from unstructured documents, and the use of corporate logos as the training set for image recognition. The lineage also shows in the use cases that HPE recommends, such as Net Promoter analysis.
Haven OnDemand currently has APIs classified as audio-video analytics, connectors, format conversion, graph analysis, experimental APIs (HP Labs Sandbox), image analysis, policy, prediction, query profile and manipulation, search, text analysis, and unstructured text indexing. I have tried out a random set and explored how the APIs are called and used.
Haven OnDemand documents only REST calls, in synchronous and asynchronous forms. Certain calls are available only for asynchronous use because they tend to be long-running. One good example is the prediction training service.
While REST calls are universally accessible to client languages, it is unusual for a major vendor to release APIs only as REST calls. Developers usually want support in their favorite programming language. Although the Haven OnDemand documentation didn’t seem to mention or refer to them at all, I searched the Internet and found a set of Haven OnDemand client libraries hiding on GitHub. Several of these were forked from IDOL OnDemand client library repositories. The clients I found supported in this repository are (in order of decreasing currency) Node.js, Salesforce Apex, Ruby (as a Gem), Python, iOS Swift, Android Java, Windows Universal 8.1, PHP, and Dynamics CRM. There seems to be only one developer maintaining these clients and handling the forums at the moment.
Haven OnDemand APIs
Most of the APIs I’ll discuss are machine learning applications. A few, such as the prediction APIs, are trainable on your own data.
Haven OnDemand’s audio-video analytics currently include only the speech recognition API, which creates a transcript of the text found in an audio or video file; it can only be called asynchronously. There are a half-dozen supported languages, plus variations. For example, U.S. English and British English are recognized differently, and telephony audio files are considered different from broadband files. Based on hints in the documentation, it would seem that HPE is working on adding new language recognizers.
I tested speech recognition with a high-quality narration file I recorded for a short video a few years ago. There are three errors in the short transcription, of which only one would have been made by a human. The service isn’t perfect, and it’s inferior to most recent speaker-trained speech recognizers, such as the ones on my cellphone and computers, but it’s better than some non-speaker-trained speech recognition services, such as the one in my car and the one that transcribes my phone messages.
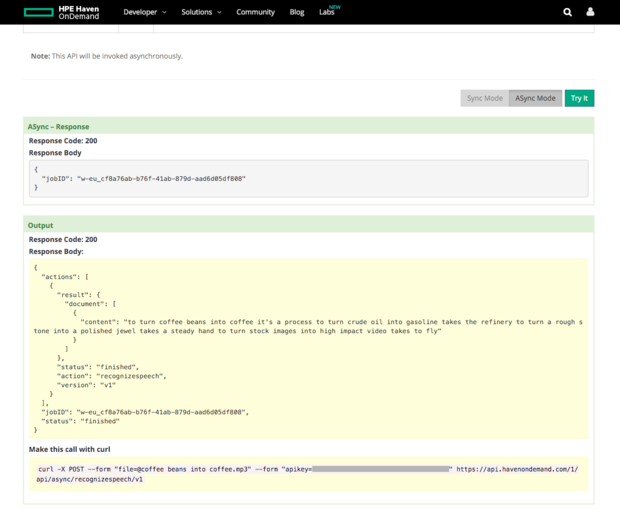
I tested Haven OnDemand’s speech recognition on a voice-over file I made for a video a few years ago. The recognition is not perfect, but it’s better than some non-speaker-trained speech recognition services, such as the one in my car.
The Haven OnDemand connectors, which allow you to retrieve information from external systems and update it through Haven OnDemand APIs, are already quite mature, basically because they are IDOL connectors. The four flavors of supported connectors allow you to retrieve content from public websites, local file systems, local SharePoint servers, and Dropbox. The file system and SharePoint connectors involve installing a local agent on the system, then scanning the desired locations on a schedule, retrieving documents, and indexing them into Haven OnDemand. SharePoint local connectors install only on Windows. Onsite file system connectors also install on Linux.
The text extraction API uses HPE KeyView to extract metadata and text content from a file that you provide. The API can handle more than 500 different file formats, drawing on the maturity of KeyView. Other format conversion APIs store files as Haven OnDemand objects, extract text from images (OCR), render documents into HTML, and extract content from container files such as ZIP, TAR, and PST archives. The OCR API has modes for document photos (good for cellphone pictures of text), scene photos (good for reading signs), document scans (from an actual scanner), and subtitles (from a TV screengrab or a video frame).
The graph analysis APIs, a set of preview services, allow you to create and explore models of relationships between entities. Currently Haven OnDemand provides a public graph data index based on the English Wikipedia data set. This appears to be more fun than “six degrees of Kevin Bacon” -- which you could easily implement using the Get Neighbors and Suggest Links APIs with a source name of “Kevin Bacon” -- but it’s not useful for real work.
Anomalies and trends
The HP Labs Sandbox contains two preview APIs: anomaly detection and trend analysis. Anomaly detection analyses structured data (in CSV format) using a novel anomaly scoring algorithm developed at HPE Labs to extract the most anomalous records (rows) in the data. That might be useful for cleaning up training data sets for predictions.
The trend analysis API discovers significant changes and trends between two groups of records in CSV format. The API analyzes all combinations of the data that you provide to find the most significant differences, using a novel analytics operation developed at HPE Labs. That might be useful for deciding when predictions need to be retrained.
Image analysis includes bar-code recognition, face detection, image recognition (corporate logos), and OCR of a document (duplicating the listing in the format conversion group). I tested bar-code recognition using HPE’s samples and, not surprisingly, got good results.

The Haven OnDemand bar-code recognition API can isolate the bar code in an image file (see the red box) and convert it to a number, even if the bar code is on a curved surface, at an angle up to about 20 degrees, or blurry. The API does not perform the additional step of looking up the bar-code number and identifying the product.
I also tried recognizing the bar code from a coupon that happened to be on my desk, and I scanned it. I couldn’t get the API request to send in synchronous mode, but it worked fine in asynchronous mode.
I tested face detection with the HPE samples, which worked fine, and I tried a slightly tricky test case from my own files (the face was a little blurry, and a bookshelf behind the face made it harder for a machine to pick out), which failed. Image recognition is currently limited to a fixed selection of corporate logos, which has limited utility.
The preview policy management APIs provide a layer on top of entity extraction, categorization, and so on for indexing and related purposes. You can define search conditions that will cause documents to be classified into a specific collection, and policies for actions to take when documents are classified into a collection, such as adding an index term or other metadata.
Predictive analytics
The preview prediction APIs are the closest services that Haven OnDemand has to Amazon Machine Learning. I was disappointed to discover that HPE’s predictive analytics only deals with binary classification problems: no multiple classifications and no regressions, never mind unguided learning. That severely limits its applicability.
On the other hand, the train prediction API automatically validates, explores, splits, and prepares the CSV or JSON data, then trains decision tree, logistic regression, naive Bayes, and support vector machine (SVM) binary classification models with multiple parameters. Then it tests the classifiers against the evaluation split of the data and publishes the best model as a service.
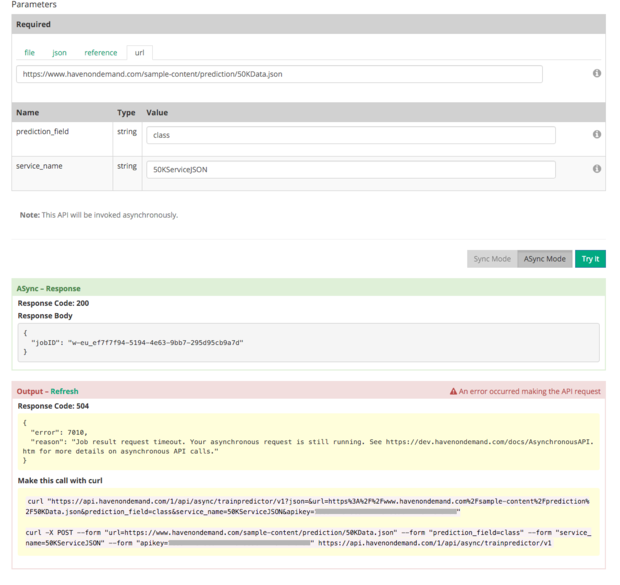
Here we see a call to the prediction training service. Note that the result has timed out, but the request is still running. It eventually succeeded.
You can then call the service to make binary predictions with confidence levels (Is this person likely to buy?) and to ask for recommendations for specific cases (What needs to change to make this person likely to buy?). The census-based sample provided works up to a point, although its recommendation answers can be somewhat silly (“If that divorced black female Ph.D. from Jamaica working for the state government were a self-employed married lawyer from the U.S., she’d make more money, at a 75 percent confidence level”).
If there’s a way to unpublish a prediction model, I haven’t found it.
The query manipulation APIs are a set of preview services that allow you to modify the queries that your users send to existing text indexes or to modify the results. You start by creating query profiles, then rules for modifying queries or results. You can add these rules to a text index, then allow users to query the text index.
Haven OnDemand search uses the IDOL engine to perform advanced searches against both public and private text indexes. The search engine supports search modification operators, Boolean operators, proximity and order operators, numeric searches, geographical searches, and metadata tags, which IDOL calls facets. Haven OnDemand has a set of six APIs for search, including related concepts and similar documents, and another seven APIs to manage unstructured text indexing.
Text analysis
There are 10 APIs for text analysis, ranging from simple autocomplete and term expansion to concept extraction and sentiment analysis. Sentiment analysis in particular can be very useful for marketing purposes: It’s not easy to determine whether people are saying good things about you when there isn’t a numerical rating that goes with a comment. The API supports 11 languages, and the language to use is an input parameter, so you might want to run the language identification API on your document first.
The HPE sample phrases for the sentiment analysis API were of course scored correctly. In my own experiments, I got non-answers for “The food tastes awful” and “The portions are small,” though “The food is awful” was correctly scored as negative with a score of -0.85.
Overall, Haven OnDemand services are comparable to the Watson services in Bluemix -- that is, mostly applications of machine learning, which you can call from your own applications and apply to your own data. There’s clearly some experience behind the text and search services from HPE IDOL and KeyView, but many of the other services show rough edges.
For example, I was disappointed by the prediction service’s limitation to binary classification problems. In its defense, however, it is still in a preview stage, and it attempts to automate the entire binary classification process, including parts that other services leave up to the analyst. Similarly, I was disappointed to discover that the image recognition service has only been trained against a database of corporate logos -- and doesn’t even have the excuse of being in preview.
It will be interesting to see how Haven OnDemand matures over the next year. I would hope it grows up nicely, but there is little evidence to support that hope.
| InfoWorld Scorecard |
Variety of models (25%)
|
Ease of development (25%)
|
Integrations (15%)
|
Performance (15%)
|
Additional services (10%)
|
Value (10%)
|
Overall Score (100%)
|
|---|---|---|---|---|---|---|---|
| HPE Haven OnDemand | 7 | 8 | 8 | 8 | 7 | 8 |
Copyright © 2016 IDG Communications, Inc.
Machine learning reviews




Haven OnDemand’s enterprise search and format conversions are the strongest services, while more...