2年半くらい画像システムを担当していたのですが、3月イッパイで異動することになりましたokzkです。
異動記念ということで、とりとめもなくエンジニアブログを書いてみます。長いです。よろしくお願いいたします。
画像システムのこれまでのストレージ事情
最初にアメブロ(以下、単にブログ)のユーザ投稿画像関連でのストレージの歴史をアレコレをまとめてみようと思います。なお、以下swiftと書いたらOpenStack Swiftのことです。流行のプログラミング言語のことではありません。
はるか昔の状況
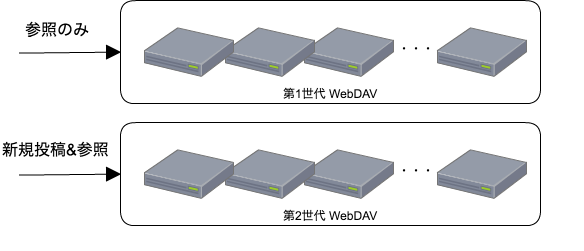
昔は単純にWebDAVを複数台並べ、イッパイになったら更に次の世代のWebDAVを追加する、というような構成で、参照時に画像URLパスに含まれる年月ベースで適切な世代のWebDAVにルーティングしていました。
(参考:画像URLのパスの例) /user_images/20160401/00/shibuya/...
新規投稿は特定のWebDAV群だけに行って、過去分のWebDAVは参照と削除だけ担当するようなイメージです。
swiftツライよ事案
過去の記事ではswiftにリプレースしたなんて、謳ってますねー。
ステキですねー。カッコイーですねー。
えー、結論からいうと、導入失敗してます。1度目は派手に。2度目は静かに。
1度目の失敗
swiftって乱暴に簡素化して説明すると、objectサーバ、containerサーバ、accountサーバという構成で、以下のような役割分担があります。
- accountサーバ: containerリストを管理
- containerサーバ: objectリストを管理
- objectサーバ: object実体を管理
実装レベルでみると、account/containerサーバの永続層はsqliteで、objectサーバの永続層は普通にobjectとファイルシステム上のファイルがマッピングされています。
でもって最初の失敗ですが、もう単純にswiftの使い方を理解してなくて、ブログの画像を全部一つのコンテナにぶち込もうとしてました。 \(^o^)/
account/containerサーバのIO分散なんか一切できていませんし、結果、画像のPUT/DELETEでレイテンシが連日ハネまくるとかの大障害を引きおこしておりました。
そんな中、まだ担当ではない私は「画像チーム、マジ大変そーやなー」とか傍目に生暖かく見守っていたのですが、2013年9月頃に一人の担当者の退職に伴い、私も画像チームを担当するハメになりました。 完全にバチがあたってますね。
そうやってできあがった200GB弱のsqliteのファイルに衝撃を受けたりしながらも、いろんな事情が重なって結局どうにもならなくなったので、WebDAVを更に追加した構成に切り戻したのが同年10月くらいです。

2度目の失敗
swiftを完全にサービスから切り離したあとは、もう一度swiftの検証のやり直しです。
- IOが分散するようaccount/containerをパスのハッシュ値で分割するようにしたり
- (分割してるとはいえ)1container当たりのファイル数が多くなり過ぎないように、さらに年月で分割したり
- アレコレ分割したせいでファイルアクセス方法が複雑化してしまったのを、swift外からは既存の画像パスでファイルにアクセスできるようにしたり
- 完全にインターナルなので認証周りの処理を外したり
などなどをswiftプラグインを書くことで対応することにしまして、まあそれなりになんとかなりそうな感触を掴むことができました。
いよいよ本番導入です。
とはいえ、一度完全にやらかしてますので、いきなり新規投稿を受け付けるのではなく、古い世代のWebDAV上の画像のファイルを移行するところから始めました。
…
……
………
…………
いや、あの、最初は良かったんですよ。最初は。。。。
ファイル移行が進むにつれて、ドンドンPUTのレイテンシがあがるようになっていって(原因は後述)、ちょーっとツライかな。。。なーんて。
そんなカンジでファイル移行に手間取っている最中に、一緒に検証したメンバーが異動でぶっこ抜かれて行ったりしてしまって、そもそものswiftの運用もままならない状況に追い込まれていきます。
とはいえ過去の分のファイルは移行してしまっていたので、そっとそのまま運用し続けることにしました。2014年の夏頃です。

WebDAVツライよ事案
WebDAVとswiftで誤魔化しながら運用している中、画像チームの当時の担当3人のうち2人が偶然同タイミングで退職するという椿事が発生しました。
そしてその直後に新規投稿を受け付けているWebDAVのIOがハネてしまって、まともに新規投稿を受け付けることができないようになる障害が続きます マジ呪われてる。
とはいえサービス側からするとそんな事情は関係ないわけで「月末までになんとかせい」という指令がその月の最終週にでる中、ジェバンニ新たにチームにジョインした二人と一緒に新規投稿分をAWS S3に逃がすという対応をやりきりました。2014年11月です。

ナニがダメだったの?
さてそろそろ画像ストレージの運用で大ハマリしたポイントについての説明なんですが、結論「ファイルシステム上のファイル数が多すぎる」でした。
通常のシステムでそんなトコでハマることはないんですけど、画像みたいにソコソコの大きさの画像が大量に保存しているようなシステムの場合、inodeがキャッシュに乗らなくなったくらいから、ものすごくIO負荷(特に更新系)が大きくなります。
これが最終的にswiftもWebDAVもどうにもならなくなった理由です。
末期では「キャッシュに載ってない状況ではlsコマンドが10秒以上かかる」という状況にまでなってました。
えー、そんなわけでー、皆様におかれましてはー、単なるファイル数だけでもサービスを殺せるという事実を覚えていただけるとウレシイですー。 どこで役にたつかは知りませんが。
WebDAVもswiftもツライよ事案
そんなこんなで新規投稿分は札束で解決できる状況にしたのですが、古くからあるWebDAVは保守部材が調達困難なレベルで老朽化してきたり、swiftもswiftで検証したメンバーがチーム内に私しかいなくなり(前述の二人同時退職事件)、完全にオペレーションもままならない状況になってる中、私の方にも「そろそろ異動してほしいんだけどー?」という別方面からの空気を読まないプレッシャーがかかるという状況がやってきてしまいました。
というわけで、本格的にどうにもならなくなる前に抜本的な解決をはかることにしました。
ファイル数という暴力に抵抗
ブログでは従来、画像投稿時にサムネイル画像も生成してストレージに保存していたのですが、サムネイル画像は参照時にオリジナル画像から動的にリサイズして生成する方式に切り換えました。
すでに参照時の画像リサイズ機能は存在していましたので対応自体はごく簡単だったのですが、コレでなんと管理対象のファイルが半分になりました。(∩´∀`)∩ワーイ
副次効果として保存するファイルが1つだけになったことで、投稿時のレイテンシも改善しました。
なお参照は元々CDNに加えて内部キャッシュ(varnish)もある構成だったこともあり、とくに目立った影響ありませんでした。
内製オブジェクトストレージの開発
WebDAVのHW老朽化はまったなしです。
swiftの運用可能人員を増やしつつ、WebDAVからswiftへの移行する、という選択肢も検討したのですが、移行に1年以上かかるという事実が判明した時点で諦めました。
すべてS3というのも考えたのですが 「そんなんちーっとも面白くないよな」という個人的ワガママでコスト面を考慮して、内製で新規にオブジェクトストレージを作ることにしました。
作ったオブジェクトストレージがどんなモノかは結構長くなるので、次節で紹介します。
最終的にはWebDAVとswiftの画像はすべて、4ヶ月ほどで内製オブジェクトストレージに移すことができました。

まとめ
ブログのユーザ画像のストレージの歴史をかいつまんで、説明しました。
現在は、昨年分のS3上の画像を内製オブジェクトストレージへ移行することで、さらなるコスト削減を目指しています。
なお、途中微妙に期間が空いているのは、ブログ以外の画像システムも担当していたり、画像システム以外のシステムを担当していて手が回らなかったからです。
# 名前を呼んではいけないKVSを使った内製オブジェクトストレージを運用者がいない状態で押し付けられた件でも、日本酒が美味しくいただけます。
(参考)他社事例
先方の内部事情は一切全く存じ上げないのですが、swiftを導入して、一年後にヤメたというGREE様のブログ記事は涙なしでは読めませんでした。
# 美味しいビールを飲みに行きたいです。
内製オブジェクトストレージの紹介
前節でちらっと紹介した内製オブジェクトストレージをもうちょっと掘り下げて紹介します。
とはいっても、別にOSSとして公開しているわけではないですので、設計とか開発の経緯を中心にまとめます。
反響があれば社外公開もあるかもしれませんが、私が4月で異動なのでどうなるかはわかりません。
要件について。
これまでの経緯を踏まえつつ、作ろうとしている画像ストレージの要件をまとめると、以下の様なモノでした。
- 新規投稿は無い。
- 既存ファイルの上書きも無い。
- 削除はあるが多くはない。
- 参照は比較的あるが、オンメモリでなければさばけないほどではない。
- ただし、1オブジェクト1ファイルの設計だと死ぬ。
- オンプレでやる以上は高集約できるようにしたい。
- HW老朽化に伴うデータ移行や、DC移設に伴うデータ移行の工数も削減したい。
- 退職・異動に伴う引き継ぎ工数も削減したい。
- 複雑な実装・運用はNG
これだけ見ると、正直、全部S3にもっていきたくなりますね。
分散システム?
通常オブジェクトストレージというと何かしらの分散システムを考えると思うのですが、分散システムは分散システム特有のしんどさ(整合性とか、一貫性とか、アンチエントロピーとか)があるため、実装したとしても、シンプルにはならず、運用工数や引き継ぎ工数が跳ね上がることが目に見えてます。
そこで「分散システムとしての設計を放棄してひたすらシンプルに作る」よう発想を転換させました。
さて、要件をよくよく考えてみると、新規投稿も上書きもないんですから、オンラインの更新トランザクション的なモノは「削除」だけです。
つまり、以下のように問題を分解することが可能です。
- 「ファイルに対して削除フラグを立てる」というトランザクションを担当するDB
- readonlyなちょっとした(!?)静的ファイル置き場
「ファイルの削除フラグ」なんて、DELETEリクエストの分だけレコードinsertすればいいだけなので余裕でメモリにのるサイズです。ということで、なにも考えずにMySQLにぶっ込むことして、残りの「静的ファイル置き場」をどうするかにだけに注力しました。
静的ファイル置き場
前述のようにファイルシステム上で1オブジェクトが1ファイルにマッピングされていると試合終了となります。ということは単純に複数のオブジェクトを一つのファイルにまとめればいいだけですので、以下のようなファイルを作成することにしました。
- 複数のオブジェクトを単純に直列化してまとめたアーカイブファイル
- 参照用に画像パスとアーカイブファイル上の位置をマッピングしたインデックスファイル
要は「参照時にパスを元にインデックスからアーカイブファイル上の位置を引いてきて、preadでオブジェクトをガツンとまとめて読み込んでレスポンスを返す」という方針です。
当然、参照用のインデックスは完全にメモリ上に展開したいですよね?
ここでもアーカイブファイルがreadonlyであるという利点が生きてきて、あらかじめtrieで辞書をつくるようにしたりとイロイロ工夫した結果、1オブジェクトあたりのインデックスのメモリ使用量は20byte程度に抑えて、全部メモリにのせることができるようになりました。
ファイルシステムのinodeのサイズを考えると、1オブジェクト1ファイル構成と比較して大幅な節約ですし、パス長の平均は80byteくらいなので単純なハッシュやtreeと比較しても省メモリです。
こんなウレシイことも!!
アーカイブファイルは一つで数TBなのですが、更新はないのでコピー時に整合性の問題は発生しません。データ移行が「単なるファイルのコピー」だけで済むようになりました。scpやncで雑にコピー可能です。
おまけに1オブジェクト1ファイルだとどうしてもランダムIOが発生してしまいますが、でっかいファイルだとシーケンシャルリード/ライトだけで済むので相当なスピードアップも見込めます。
また最終的なファイル数も少ないので、データ移行時に地味にメンドクサイ「移行モレのチェック」もとても簡単です。もしモレてしまった場合でも、数千万オブジェクト単位でアクセス不能になるのですぐに判明します。
加えて参照時のIOに関しても、個別ファイルのinodeのルックアップ等が不要になったおかげで、WebDAV時よりはるかに高集約化しているにも関わらず、iostatのavgrq-szが一桁増えてくれて、結果、格段に負荷は下がってくれました。
以上を踏まえて最終的な構成
最終的な構成は以下のようなカタチです。

ここまでに至る経緯とかは横において、出来上がったモノだけみてみると、
- プロキシサーバ: DBを引いてルールベースで適切なデータサーバにルーティングするリバースプロキシ
- ルーティングに必要なメタデータもDBに突っ込んでます。
- データサーバ: ローカルのアーカイブファイルからオブジェクトを返すだけのhttpサーバ
本当に面白みのない、たいしたコトない構成ですね。実際、ソースコードもコアだけなら数時間で全部読み込めるレベルです。
これは、内製のアプリケーションは「書いた瞬間から負債になる」というやるせない事実を踏まえて、そもそも極限までシンプルにすることでその負債の量を減らす、という設計上の狙いの一つでもあります。
ということで「退職・異動に伴う引き継ぎ工数の削減」もなし崩し的に実現出来てる……と評価してもらえるといいなぁ。。。
一応耐障害性についても
MySQLはレプリを組んでゴニョゴニョゴニョというよくある構成ということで、ググっていただければいいので割愛します。
アーカイブファイルを置いてあるサーバに関しては、更新もないので同じアーカイブファイルを複数台に配置しておくだけです。
サーバ吹っ飛んだら、生きているサーバから手動でファイル転送するだけ、という手動アンチエントロピー対応を想定しています。
実にシンプルですね。
サーバは死に方によってはパーツ交換の保守だけで復活できますし、高集約している場合に数日単位でかかるファイルコピーが自動で動くよりもヒトが確認しながら対応したほうが最終的には運用負荷が低いんじゃねーの? というのを言い訳に手を抜いたわけです。
なお、ディスク容量節約のためHDFSのイレイジャーコーディングみたいな実装もちょっとは検討はしましたが、実装と運用が複雑になりそうなので結局採用しませんでした。
まとめ
画像チームで作ったオブジェクトストレージの設計の紹介をしました。
かなりユースケースが限られるモノですが、冗談みたいに大量の小さいファイルを扱う場合などには参考にしていただけると幸いです。
余談
設計固めて、WebDAVのファイルのアーカイブを始めたあとくらいに、@brfrn169にfacebookのhaystackとf4というオブジェクトストレージの論文を教えてもらいました。設計方向とかに共通部分が多いので、よければソチラも参考にしていただければと思います。つーか、もっと早く教えてくれよ!!!
画像を扱うサービスのベストプラクティス
今度は視点をガラッとかえて、ユーザ投稿の画像を受け付けるサービス開発において、あらかじめ考慮しておくと良いと思われるポイントを列挙していきます。
最初に謝っておきますが、ベストプラクティスなんてタイトル詐欺感満載です。ゴメンナサイ。
# ところどころ社内向け情報が混ざってますが、反響があれば社外公開されるかもしれません。
同一URLの画像の更新を不可にしよう。
画像を扱うオペレーションには、乱暴には以下の4種類があります。
- 新規追加
- 参照
- 更新
- 削除
このうち「更新」については設計上できないようにしましょう。
もし更新が必要なら、アプリケーションを工夫して「別パスでアップロードしなおしてリンクを差し替え、古い方を削除する」としてください。
こうすることで、CDNやブラウザのキャッシュに悩まされずに済みますし、更新がない分だけ積極的にブラウザキャッシュを有効活用できるので、ユーザ的にも表示が早くなってウレシイですし、コストに直結する通信量も削減できます。
逆に更新を許容してしまうと、キャッシュパージの問題などに、ずーーーっと悩まされることになります。ツライです。
また、結果整合性のオブジェクトストレージも採用しやすくなりますし、前述の内製オブジェクトストレージみたいに「更新がないからこそ採用できるストレージ」というのもあります。将来的な選択肢を残す意味でも画像の上書き更新は設計時点で排除しておきましょう。
画像URLパスにオブジェクトストレージの仕様や制限を反映させない
オブジェクトストレージにはそれぞれ特有の制限やベストプラクティスがあります。
- swiftではオブジェクトのパスが"/v1/AUTH_...."になる
- S3ではキー名が連続するパターンを避けることが推奨されている
その制限やベストプラクティスには従うべきなのですが、画像URLのパスはそれ自体名前空間であり、サービスの仕様です。
特定のオブジェクトストレージ特有の事情を反映させてしまうと、他のオブジェクトストレージに乗り換える際に大きな負担となります。
ロックインに覚悟完了していない場合は、オブジェクトストレージ特有の事情とサービスの仕様とを吸収するプロキシ的なモノを挟むとよいでしょう。
# (社内限り)S3用のプロキシ、あるよ。
画像のパスから世代を判別できるようにしよう
ユーザ投稿の画像は一般的に「直近に投稿された画像ほどよく参照される」という傾向があります。これは言い換えれば「昔に投稿された画像はほとんど参照されない」ということです。
このため、直近のモノをHotなオブジェクトストレージに、そうでないモノをWarmなオブジェクトストレージに、というような世代別な管理がコスト・性能的に効果的であるケースが(超大規模になれば)あります。
そのため、画像URLに投稿年月を含めておくなどしてルールベースで世代判別できるようにしておきましょう。
サービス開発の最初期に複数のオブジェクトストレージを使うことなんてアリエナイと思いますが、画像URLパスをその場その場の行き当たりばったりで決定してしまうと、ルールベースで世代判別不能になってしまい、将来的な選択肢を失うことになります。
関連画像を事前生成する場合は、そのパスからオリジナル画像のパスを生成可能にしておこう
サムネイル画像のように関連画像を投稿時に一緒に生成してストレージに保存する、という設計は比較的よくあると思います。その場合のサムネイル画像のURLをからオリジナル画像のURLをルールベースで変換できるように、サムネイル画像のURLを決定しましょう。
時間がたち参照が減るにつれて、オリジナル以外の画像をストレージに保持するコストの方が高くなるタイミングがいずれはやってきます。 そうです、ファイル数は暴力です。
そんな時はサムネイル画像のストレージ保存をやめて、リクエストに対してオリジナル画像をオンザフライで変換したものをレスポンスで返すとよいのですが、そのためには「オリジナル画像のパス」がワカラナイと詰みます。ツライです。
なお、最初から関連画像はすべてオンザフライで変換するようにするというのもアリです。
small_light系のモジュールを利用してもよいですし、自分たちで画像変換サービスを運用するのがメンドウならakamaiなどのCDNのサービスを利用するのも手です。
# (社内限り)画像チームで作成した画像変換プロキシモジュール、あるよ。
オンザフライの画像変換をするときはメモリ使用量を制限しておこう
画像変換の内容によっては、1リクエストでものすごく大量のメモリが必要になってしまうケースが出てきます。ある程度で上限を設けておきましょう。
さもないとOSのOOM killerでサーバプロセスごとお亡くなりになってしまいます。
オンザフライの画像変換をするときはthundering herdに気をつけよう
CDNを用意していても、投稿直後などにキャッシュヒットしなかった画像変換クエリが大量に流れてくるケースがあります。
通常は問題なくても、アニメーションGIFの変換のようなとてもとても時間のかかる変換アクセスが大量に流れてくると、その勢いで画像変換サーバが全滅したりします。
構成複雑になるので初期で対応する必要はないと思いますが、問題になった場合は同一の画像変換リクエストを束ねるような構成を検討しましょう。
VarnishやApache Traffic Serverなどが候補になると思います。
exif情報の取り扱いを考慮しよう
ユーザ投稿の画像ではexif情報がそのまま入っているケースが非常に多いです。
GPSの情報のようにそれなりにセンシティブなデータもあるので、ユーザのプライバシー保護のために(少なくともデフォルトでは)削除するようにしましょう。
# (社内限り)golangのexif削除ライブラリ、あるよ。
exif情報をクレジット的な用途で使っている方もいらっしゃるので、その場合はexif情報を残すオプションを用意するのはアリです。
初期から自前でストレージを運用するのはやめよう
初期は黙ってS3とかのマネージドサービスを利用しましょう。
自前運用を検討するのは、スケールメリットがでる規模になってからでいいです。
初期からCDNを利用を検討しよう
最近はオンラインでポチポチするだけで使えるCDNがいくつもあります。
コスト的にも有利なケースが多いですし、運用で手がかかるモノではないので積極的に利用を検討しましょう。
なお、CDNによってはポリシー的にNGなコンテンツがあるケースがあります。アダルト系のコンテンツを扱う場合は特に注意しましょう。
最後に身も蓋もないことを
手に負えないほど大規模にならなければ、ぶっちゃけ後からでもどうにかなります。
サービス作るときは、イーカンジに手を抜きましょう。
それでは皆様、ステキなエンジニアライフを。