حافظه کش L2 ،L1 و L3 چیست و چه تاثیری در عملکرد پردازنده دارد؟



تقریبا تمام پردازندهها از پردازندههای کممصرف و کمتوانی مانند Cortex-A5 آرم تا پردازندههای قدرتمندی همچون Core i7 اینتل همگی از حافظهی پرسرعتی بهنام کش (Cache) بهره میبرند. حتی میکروکنترلرهای ردهبالا نیز عموما کَش کوچکی دارند. با وجود اینکه در طراحی آنها مصرف انرژی اهمیت زیادی دارد و کش نیز انرژی مصرف میکند، اما مزیتهای حافظهی کش آنقدر مهم هستند که استفاده از کش را توجیه میکند.
کشینگ و استفاده از کش اختراع شد تا یک مشکل جدی را حل کند. در دهههای اولیهی ظهور کامپیوتر، حافظهی اصلی بهشدت کند و بسیار گران بود و از طرفی پردازندهها نیز چندان سریع نبودند. در دههی ۱۹۸۰ اختلاف سرعت بین حافظه و پردازنده افزایش یافت و سرعت کلاکِ میکروپروسسورها مدام در حال افزایش بود. در این شرایط همچنان حافظهها کند بودند و درواقع نمیتوانستند پا به پای پردازندهها دسترسی به اطلاعات را فراهم کنند. اینجا بود که لزوم ساخت حافظههای سریعتر حس شد. در نمودار زیر میتوانید رشد سرعت حافظههای DRAM و CPUها را طی سالهای ۱۹۸۰ تا ۲۰۰۰ مشاهده کنید:
در سال ۱۹۸۰ کش در میکروپروسسورها وجود نداشت. در سال ۱۹۹۵ استفاده از سطح دوم کش رواج یافت.
حافظه کش چیست و چطور کار میکند؟
کش به زبان ساده یک حافظهی بسیار سریع است که دقیقا درکنار واحدهای منطقی پردازندهی مرکزی قرار میگیرد. البته قطعا حافظهی کش بیش از این تعریف یک خطی در قدرت و سرعت پردازنده کاربرد و تأثیر دارد.
برای درک ابتدایی ساختار و کاربرد کش، یک حافظهی فرضی بدون نقص را در نظر بگیرید. سیستم ذخیرهسازی جادویی ما، بینهایت سریع است و توانایی ذخیرهسازی بینهایت تراکنش داده را دارد. همچنین دادههای موجود در سیستم مذکور، برای همیشه امن هستند. قطعا چنین حافظهای وجود خارجی ندارد، اما اگر این سیستم توسعه پیدا میکرد، طراحی پردازندهها بسیار آسان میشد. پردازندهها در چنین فرضیهای تنها برای انجام فرایندهای ریاضی به واحدهای منطقی نیاز پیدا میکردند. یک سیستم هم برای مدیریت تبادل دادهها مورد استفاده قرار میگرفت. ازآنجاکه سیستم جادویی فرضی، امکان ارسال و دریافت آنی تمامی اعداد را داشت، هیچیک از واحدهای منطقی پردازنده، نیازی به منتظر ماندن برای تبادل دادهها نداشتند.
همانطور که میدانیم، سیستم جادویی فرضیهی بالا وجود ندارد و احتمال توسعهی آن نیز به صفر میل میکند. بهجای سیستم مذکور، درحالحاضر درایوهای حالت جامد را در دست داریم که حتی بهترین نمونهها در میان آنها نیز توانایی مدیریت تمامی تبادلهای دادهای موردنیاز پردازندههای عادی را ندارند.
چرا حافظه SSD هم توانایی مدیریت تمام نیازهای دادهای پردازنده را ندارند؟ پردازندههای مدرن، سرعت عملکرد زیادی دارند و بهعنوان مثال، در هر سیکل کلاک، امکان جمع کردن دو مقدار عدد صحیح ۶۴ بیتی را با هم دارند. به بیان دیگر، چنین عملیاتی برای یک پردازندهی چهار گیگاهرتزی، تنها ۰/۰۰۰۰۰۰۰۰۰۲۵ یا یکچهارم نانوثانیه طول میکشد. حال تصور کنید که هارد درایوهای مکانیکی، تنها برای پیدا کردن داده به چند هزار نانوثانیه نیاز دارند. بهعلاوه، زمان تبادل داده را هم باید به این مقدار اضافه کنید. حافظههای SSD با سرعت بسیار بالا هم برای پیدا کردن داده به چندده یا چندصد نانوثانیه زمان نیاز دارند.
درایوهای ذخیرهسازی سریع را نمیتوان در داخل پردازندهها توسعه داد. درنتیجه همیشه یک فاصلهی فیزیکی بین بخش ذخیرهسازی و پردازندهی مرکزی وجود دارد. همین فاصله، زمان دسترسی و جابهجایی داده را افزایش میدهد که موجب بدتر شدن شرایط میشود.
برای رفع چالش بالا، باید سیستم ذخیرهسازی دادهی دیگری بین پردازنده و حافظه ذخیره سازی اصلی اضافه کنیم. حافظهی جدید، باید سریعتر از درایو بوده و توانایی مدیریت تمامی فرایندهای تبادل داده را بهصورت همزمان داشته باشد. از همه مهمتر، این حافظه باید هرچه بیشتر به پردازنده نزدیک باشد. حافظهای که ترکیبی از پیشنیازها را داشته باشد، در کامپیوترهای شخصی وجود دارد و آن را بهنام رم (RAM) میشناسیم. به بیان بهتر، نام DRAM برای این نوع از حافظه استفاده میشود که توانایی تبادل دادهها را با سرعتی بسیار بیشتر از هر درایو ذخیرهسازی دارد.
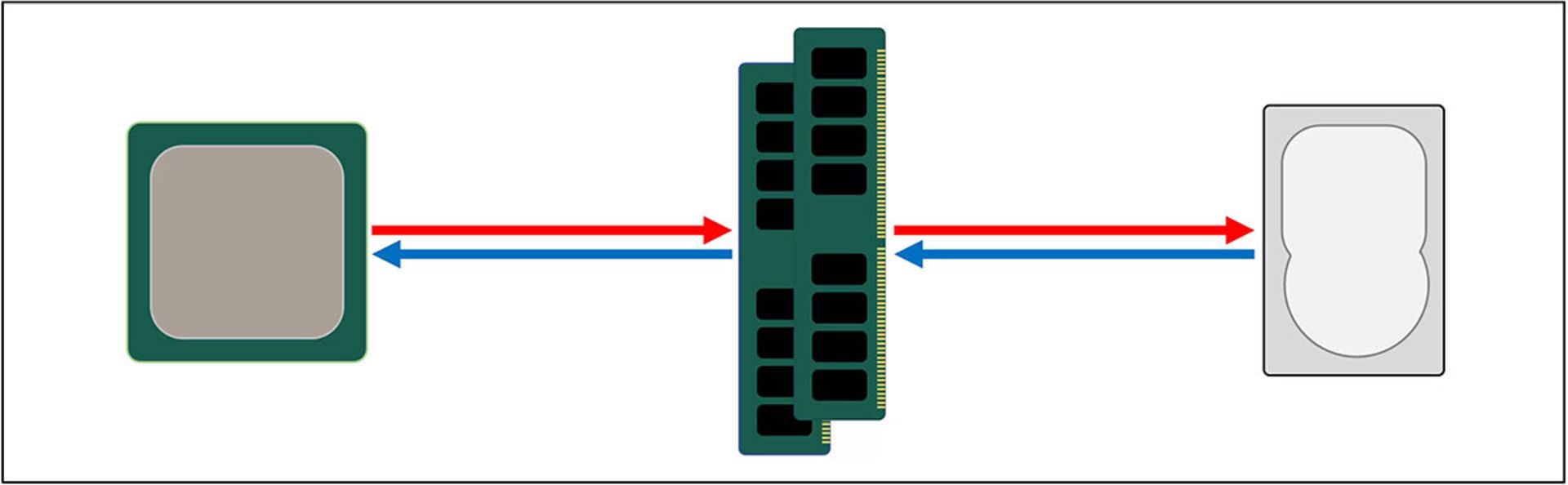
حافظهی رم با وجود سرعت بالایی که به کامپیوتر ارائه میکند، توانایی ذخیرهی حجم زیادی از داده را ندارد. در مقام مقایسه، جالب است بدانید تراشههای بزرگ DDR4 هر یک توانایی ذخیرهی ۳۲ گیگابیت را دارند، درحالیکه بزرگترین هارد ها، ظرفیتی چهار هزار برابر بیشتر را ارائه میکنند.
با وجود اینکه اضافه کردن رم، مشکل سرعت در تبادل داده را از بین میبرد، برای بهبود سیستم به بخشهای سختافزاری و نرمافزاری دیگری هم نیاز پیدا خواهیم کرد. این سیستمهای اضافه، تصمیم میگیرند که چه دادهای باید در حافظهی محدود DRAM بهصورت آماده برای پردازندهی مرکزی، نگهداری شود.
حافظههای DRAM برخلاف درایوهای مرسوم ذخیرهسازی، امکان تولید بهصورت تراشه را دارند که بهنام embedded DRAM شناخته میشود. بااینحال، باز هم ابعاد بسیار کوچک پردازنده مانع از آن میشود که تراشههای DRAM را در CPU جانمایی کنیم.
اکثر حافظههای DRAM در نزدیکترین موقعیت نسبت به پردازنده قرار دارند و روی مادربرد نصب میشوند. همیشه جدیدترین قطعه به CPU، حافظهی DRAM است، اما باز هم توانایی ارائهی سرعت بالای کافی را ندارد. DRAM برای پیدا کردن دادههای مدنظر، به ۱۰۰ نانوثانیه زمان نیاز داشته و البته حداقل توانایی جابهجایی میلیاردها بیت داده را در هر ثانیه دارد. ظاهرا برای افزایش هرچه سریعتر سرعت انتقال داده، به یک بخش ذخیرهسازی دیگر بین واحدهای پردازشی CPU و DRAM نیاز داریم.
پیش از رسیدن به راهکار نهایی، باید یک قطعهی ذخیرهسازی دیگر را نیز بررسی کنیم. SRAM یا Static Random Access Mempory تفاوتهایی کلی با DRAM دارد. DRAM از خازنهای میکروسکوپی برای ذخیرهسازی داده بهصورت بار الکتریکی استفاده میکند. در SRAM از ترانزیستور برای همین منظور استفاده میشود که سرعتی بسیار بالا و نزدیک به واحدهای منطقی پردازندهی مرکزی دارد. SRAM سرعتی حدود ۱۰ برابر DRAM دارد.
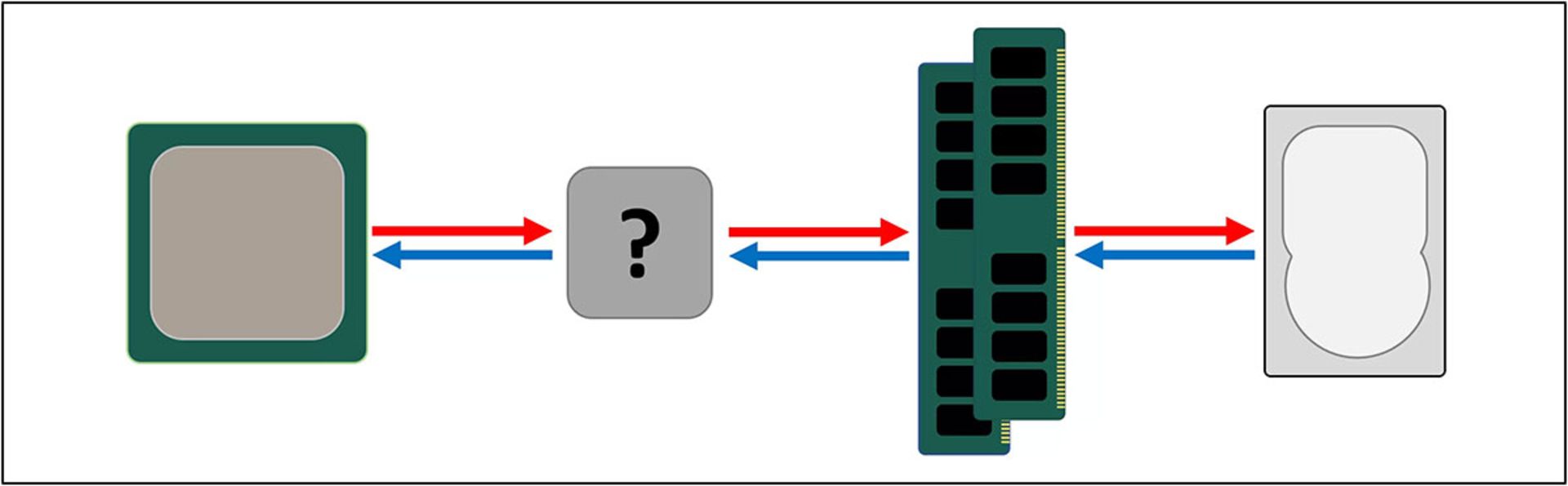
حافظههای SRAM با وجود سرعت بیشتر، باز هم محدودیت فضا دارند. حافظههای مبتنی بر ترانزیستور، فضای بسیار بیشتری نسبت به DRAM اشغال میکنند. یک ماژول SRAM با ابعاد فیزکی نزدیک به یک ماژول DDR4، تنها ۱۰۰ مگابایت حافظهی ذخیرهسازی دارد. البته ازآنجاکه SRAM با فرایندی شبیه به ساخت CPU تولید میشود، میتوان از آن در داخل تراشهی پردازندهی مرکزی استفاده و حافظه را هرچه نزدیکتر به واحدهای منطقی جانمایی کرد.
در مراحل بالا، در هر مرتبه که یک فرایند ذخیرهسازی بین درایو ذخیرهسازی و پردازنده اضافه کردیم، سرعت افزایش پیدا کرد و ظرفیت کمتر شد. هنوز هم میتوان در فرایندهای بالا، مراحلی را اضافه کرد تا حافظههایی با ظرفیت کمتر و سرعت بیشتر، به سیستم اضافه شوند.
باتوجهبه توضیحات بالا، اکنون میتوان تعریف فنی و دقیقتری از حافظهی کش ارائه کرد. حافظهی کش، تعدادی بلوک حافظهی SRAM است که همگی در داخل پردازنده قرار دارند. این واحدها وظیفه دارند تا واحدهای منطقی پردازنده را همیشه مشغول نگه دارند. آنها داده را با سرعتهایی بسیار بالا به واحدهای منطقی ارسال کرده و از آنها دریافت میکنند.
کش یا پارکینگ طبقاتی
همانطور که دیدید، کش به این دلیل ایجاد شد که هیچ سیستم جادویی ذخیرهسازی برای پاسخ به نیازهای شدید دادهای واحدهای منطقی پردازنده وجود ندارد. پردازندههای مدرن مرکزی و گرافیکی امروزی، همگی دارای تعدادی بلوک SRAM هستند که ازلحاظ داخلی بهصورت سلسلهمراتبی دستهبندی شدهاند. درنهایت، ترتیبی از حافظههای کش شبیه به تصویر زیر، جانمایی شدهاند.
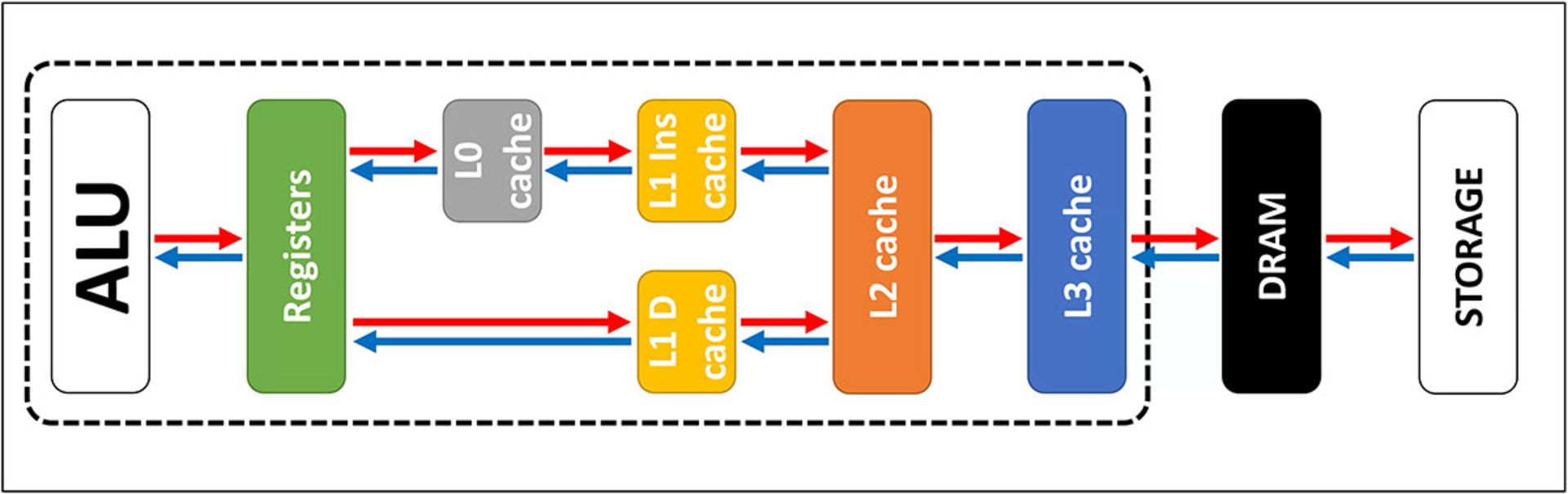
در تصویر بالا، مستطیل خطچین پردازنده را نشان میدهد. ALU یا واحدهای منطقی محاسباتی، در سمت چپ قرار دارند که وظیفهی اصلی محاسبههای وظایف را برعهده میگیرند. نزدیکترین واحد ذخیرهسازی به واحدهای منطقی، اصولا در دستهبندی کش جای نمیگیرد و همانطور که میبینید، بهنام Registers شناخته میشود. واحد مذکور، گروهی از فایلهای موسوم به رجیستر است.
هریک از واحدهای رجیستر، یک عدد تکی را نگهداری میکنند، مثلا یک عدد صحیح ۶۴ بیتی. مقادیر هر بخش میتواند هر نوع دادهای باشد. مثلا در هر رجیستر شاید کد یک دستورالعمل خاص یا حتی آدرس مموری دادهای دیگر ذخیره شود. فایل رجیستر در یک پردازندهی رومیزی بسیار کوچک است. بهعنوان مثال، در پردازندهی Core i9-9900K در هر هسته، دو مجموعهی رجیستر قرار دارد. دستهی مخصوص اعداد صحیح، تنها ۱۸۰ رجیستر ۶۴ بیتی دارد. رجیستر دیگر برای اعداد برداری استفاده میشود و ظرفیت ۱۶۸ ورودی ۲۵۶ بیتی دارد. درنتیجه، ظرفیت کل فایل رجیستر برای هر هسته، کمی کمتر از هفت کیلوبایت خواهد بود. در مقام مقایسه، فایلهای رجیستر در مجموعههای Streaming Multiprocessors مثل پردازندهی گرافیکی GeForce RTX 2080 Ti، ابعاد ۲۵۶ کیلوبایتی دارند. Streaming Multiprocessors، تراشههایی هستند که در پردازندهی گرافیکی عملکردی شبیه به CPU دارند.
رجیسترها ازنوع SRAM هستند، اما سرعت آنها با واحدهای منطقی متصل برابری میکند. درنتیجه آنها داده را در هر چرخهی کلاک، با ALU تبادل میکنند. همانطور که دیدید، این واحدها برای ذخیرهسازی دادهی زیادی طراحی نشدهاند. درنتیجه، همیشه یک واحد بزرگتر ذخیرهسازی داده درکنار آنها وجود دارد که همان نام آشنای حافظهی کش L1 را برای آن انتخاب میکنیم.
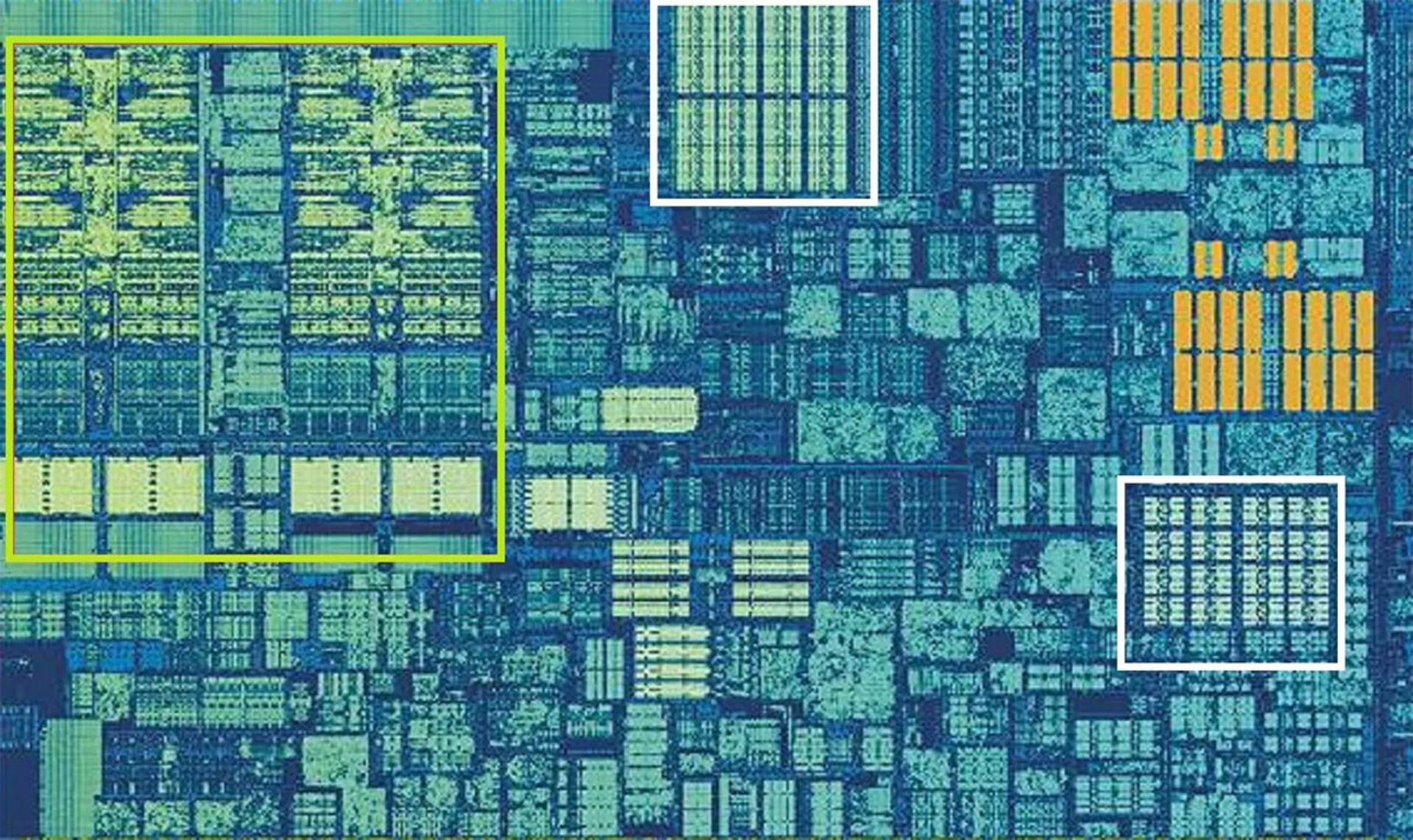
درتصویر بالا، نمای نزدیکی از یک هستهی پردازندهی رومیزی اینتل اسکایلیک را مشاهده میکنید. واحدهای ALU و رجیستر در بالا و سمت چپ تصویر دیده میشوند که در داخل چهارضلعی سبز قرار دارند. در سمت راست و بالای تصویر، حافظهی کش L1 در چهارضلعی سفید دیده میشود. این حافظه ظرفیت محدود ۳۲ کیلوبایتی دارد. همانطور که میبینید، L1 مانند رجیستر در فاصلهی بسیار نزدیک به واحدهای منطقی قرار دارد و سرعتی برابر با آنها را ارائه میکند.
چهارضلعی سفیدرنگ دیگر در تصویر بالا، کش موسوم به Level 1 Instruction را نشان میدهد که آن هم ظرفیت محدود ۳۲ کیلوبایتی دارد. همانطور که از نام حافظه بر میآید، وظیفهی ذخیرهسازی دستورهای متعددی را برعهده دارد که آمادهی تقسیمشدن به عملیات کوچکتر موسوم به μops هستند و درنهایت برای ALU ارسال میشوند. برای این دستورها نیز یک حافظهی کش وجود دارد که بهنام L0 شناخته میشود. این حافظه کوچکتر است و در فاصلهای نزدیکتر نسبت به حافظهی L1 قرار میگیرد. L0 تنها توانایی ذخیرهسازی ۱،۵۰۰ عملیات را دارد.
شاید از خود بپرسید که چرا بلوکهای حافظهی SRAM در پردازنده کوچک هستند و آنها را در ظرفیتهای مگابایتی تولید نمیکنند. دادهها و دستورالعملهایی که در کش نگهداری میشوند، فضایی برابر با واحدهای منطقی در تراشهی پردازنده اشغال میکنند. درنتیجه افزایش ابعاد آنها منجر به افزایش ابعاد کل قالب تراشه میشود. البته دلیل اصلی پایین بودن ظرفیت در حد کیلوبایت این است که با افزایش ابعاد سیستم ذخیرهسازی، زمان موردنیاز برای دسترسی به داده هم افزایش پیدا میکند. حافظهی L1 باید سرعت عمل بسیار زیادی داشته باشد. به همین دلیل باید بین ابعاد و سرعت تعادل ایجاد شود. برای دسترسی به داده در این حافظه و استخراج آن، حداقل به پنج سیکل کلاک نیاز داریم.
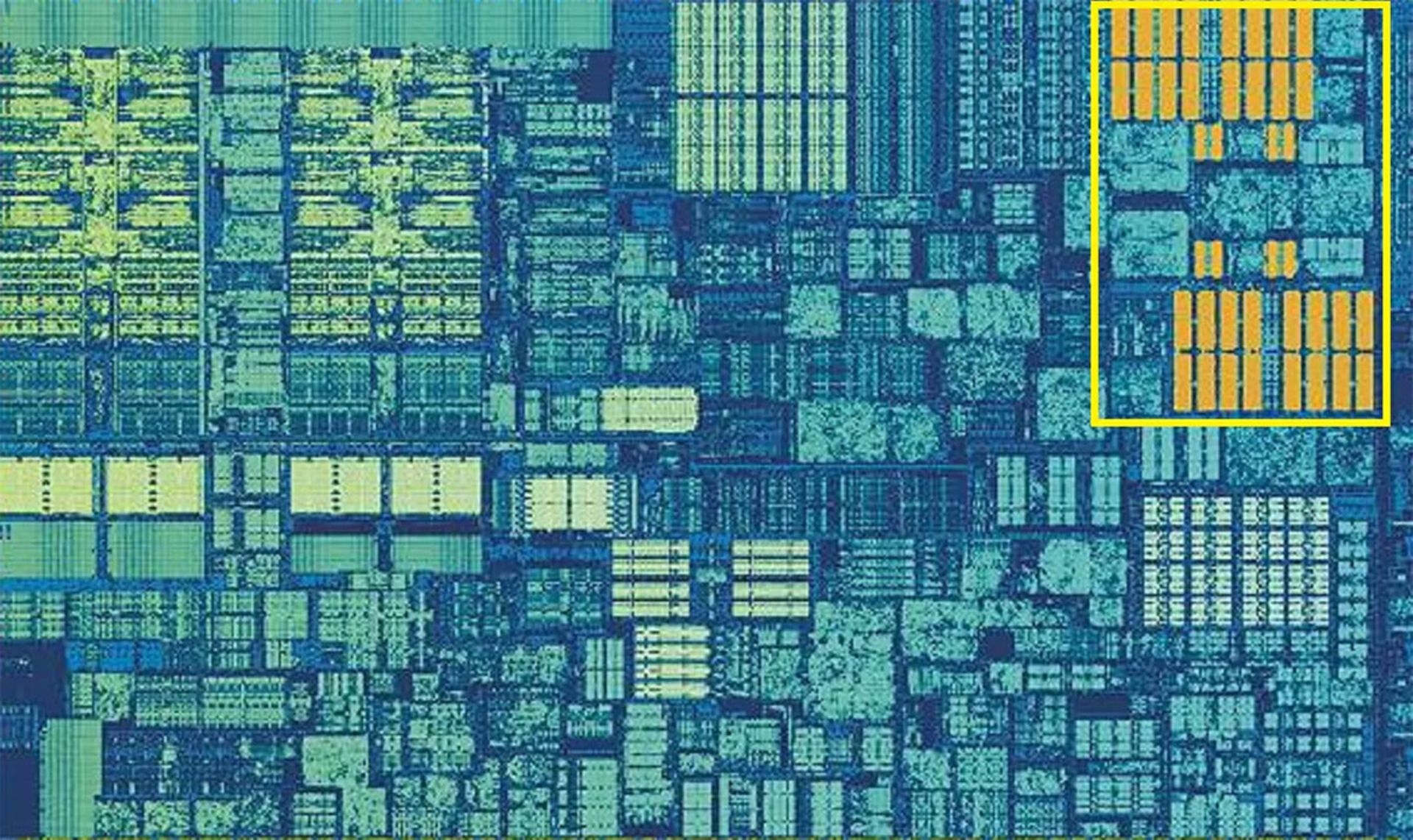
اگر در یک پردازنده تنها از یک حافظهی کش استفاده میشد، بهرهوری و کارایی با مانع بزرگی روبهرو میشد. به همین دلیل لایهی دیگر ذخیرهساز هم نیاز خواهد بود که بهنام Level 2 یا همان L2 شناخته میشود و دستورالعمل و داده را نگهداری میکند.
حافظهی L2 همیشه بزرگتر از L1 است. در پردازندههای AMD Zen 2 شاهد استفاده از حافظههای L2 با ظرفیت ۵۱۲ کیلوبایت هستیم که دادههای موردنیاز L1 را همیشه دردسترس قرار میدهند. البته همانطور که گفته شد، با افزایش ابعاد حافظه، سرعت کاهش پیدا میکند. درنتیجه حافظههای L2 برای پیدا کردن داده نسبت به L1 به دوبرابر زمان نیاز دارند. در گذشته و در دوران پردازندههای پنتیوم، کش L2 بهصورت بخشی جدا در رم یا مادربرد استفاده میشد و بهمرور به تراشهی اصلی CPU رسید. همین مسیر، برای اضافه شدن کش جدید به پردازندهها طی شد و لایهی جدید، همزمان با توسعهی پردازندههای چندهستهای به تراشههای اصلی اضافه شد.

تصویر بالا از تراشهی اینتل Kaby Lake، چهار هسته را در سمت چپ و مرکز نشان میدهد (نیمی از تراشه در سمت راست، توسط پردازندهی گرافیکی یکپارچه اشغال شده است). هر هسته، مجموعهای اختصاصی از حافظههای کش L1 و L2 دارد که در چهارضلعیهای سفید و زرد میبینید. البته هستهها مجهز به یک لایهی سوم از حافظهی SRAM نیز هستند.
کش L3 یا Level 3 در اطراف یک هستهی تکی دیده شده، اما با هستههای دیگر به اشتراک گذاشته میشود. درواقع هر هسته میتواند آزادانه به دادههای موجود در کش L3 دیگر دسترسی پیدا کند. این حافظهها ظرفیت بسیار بیشتری به کشهای دیگر دارند و عموما بین دو تا ۳۲ مگابایت ظرفیت ارائه میکنند. البته سرعت آنها کمتر است و بهصورت میانگین به ۳۰ چرخهی کلاک میرسد. از همه مهمتر، اگر هستهای به دادههای موجود در بلوک کش در فاصلهی دور نیاز داشته باشد، سرعت کاهش پیدا میکند.
در تصویر زیر، یک هستهی تکی در معماری AMD Zen 2 را مشاهده میکنید. کش L1 با ظرفیت ۳۲ کیلوبایت در مستطیلهای سفید، کش L2 با ظرفیت ۵۱۲ کیلوبایت در مستطیلهای زرد و کش بزرگ چهار مگابایتی L3 در مستطیل قرمز دیده میشود.

با مقایسهی ابعاد مستطیلها این سؤال ایجاد میشود که چرا حافظهی کوچک ۳۲ کیلوبایتی L1، فضای بیشتری نسبت به حافظههای دیگر اشغال کرده است؟
مفهومی مهمتر از اعداد
کش، با افزایش سرعت تبادل داده به واحدهای منطقی و نگه داشتن یک کپی از دستورالعملهای رایج و پرکاربرد در فاصلهای نزدیک به واحدها، قدرت و بهرهوری پردازنده را افزایش میدهد. اطلاعاتی که در کش ذخیره شده، به دو بخش تقسیم میشود: خود داده و موقعیت آن در حافظهی ذخیرهسازی اصلی سیستم. موقعیت یا آدرس، بهنام برچسب یا تگ کش شناخته میشود.
وقتی پردازنده، یک عملیات را با نیاز به خواندن یا نوشتن داده از حافظه اجرا میکند، ابتدا تگهای موجود در کش L1 بررسی میشوند. اگر تگ مناسب در L1 موجود باشد، دسترسی به داده بهسرعت رخ میدهد (Cache Hit)، اگر هم تگ در حافظهی کش سطح پایین پیدا نشود، رخداد موسوم به Cache Miss اتفاق میافتد. در چنین وضعیتی یک تگ جدید در L1 ساخته شده و سایر بخشهای معماری پردازنده، وارد عمل میشود تا داده را در کشهای سطوح دیگر جستوجو کند. درنهایت شاید پردازنده مجبور به مراجعه به حافظهی ذخیرهسازی اصلی بشود. ازطرفی برای ایجاد فضا در حافظهی L1، همیشه باید بخش دیگر از داخل L2 خارج شود.
فرایندی که در بالا توضیح داده شد باعث میشود که همیشه، دادهها در روندی تصادفی جابهجا شوند که البته فرایند در چند چرخهی محدود پردازنده رخ میدهد. برای رسیدن به چنین عملکردی به ساختاری پیچیده نیاز داریم که مدیریت SRAM و دادهها را برعهده بگیرد. به بیان سادهتر، اگر یک هستهی پردانده تنها یک واحد منطقی داشته باشد، حافظهی L1 بسیار یادهتر میشود، اما ازآنجاکه چندین واحد منطقی در پردازنده داریم، کش برای حفظ جریان دادهها به چندین اتصال نیاز پیدا میکند.
با استفاده از نرمافزارهای رایگان مانند CPU-Z میتوانید اطلاعاتی کلی از ساختار پردازندهی مرکزی خود به دست بیاورید. درک این اطلاعات، کمک شایانی به درک بهتر ساختار کش میکند. یکی از مهمترین المانهای اطلاعاتی، set associative نام دارد که قوانین و دستورالعملهای چگونگی کپی کردن بلوکهای داده از حافظهی سیستم به کش را مشخص میکند.
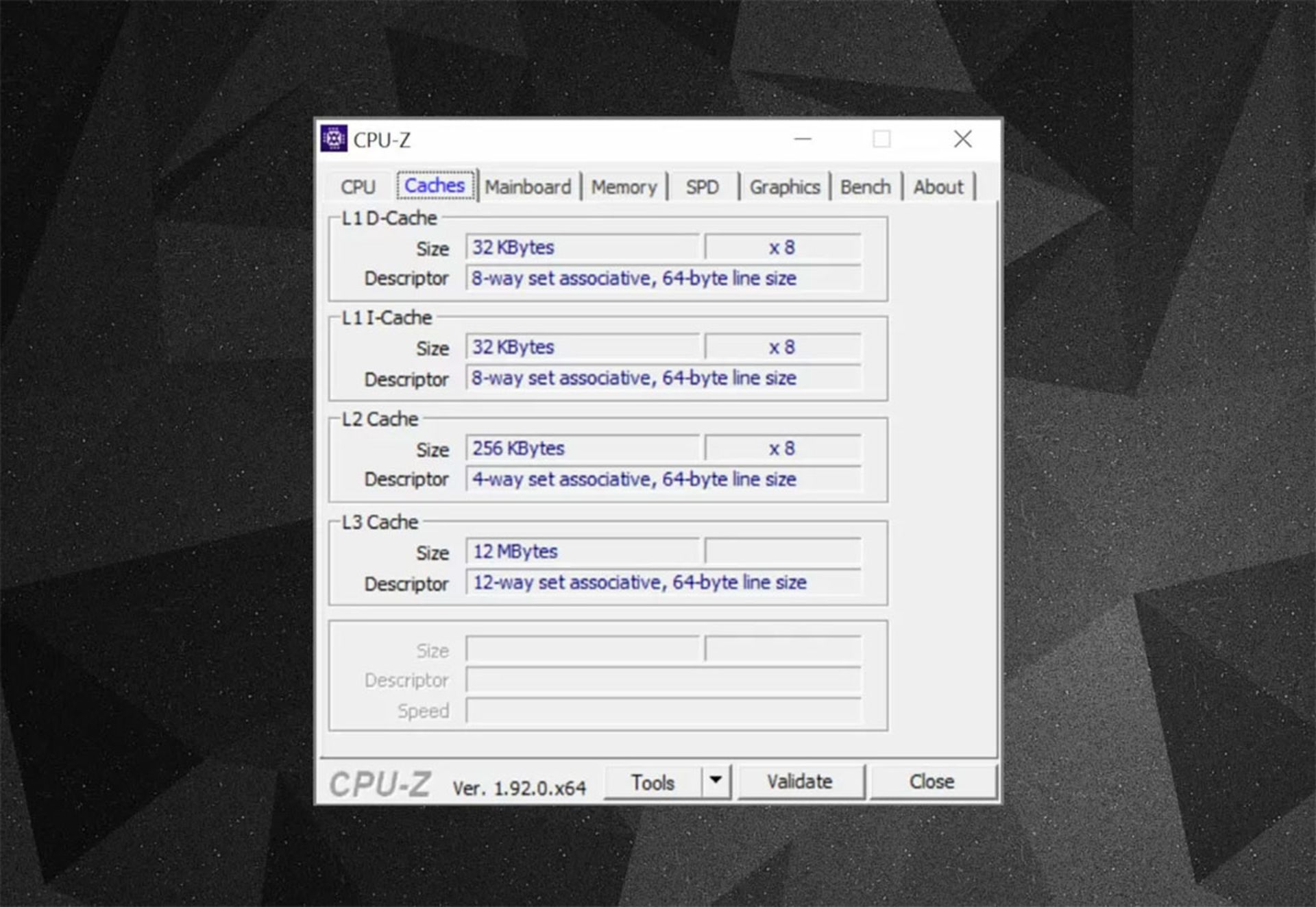
اطلاعات کش بالا، متعلق به پردازندهی Core i7-9700K هستند. حافظههای کش L1 در این پردازنده هرکدام به ۶۴ بلوک کوچکتر تقسیم میشوند که Sets نام دارند. بهعلاوه، هر بخش کوچکتر مجددا به بخشهای کوچکتری بهنام cache lines تقسیم میشوند که هرکدام ابعاد ۶۴ بایتی دارند. بخش set associatives یعنی یک بلوک داده از حافظهی سیستمی در مجموعهای مشخص به cache lines مرتبط شده است.
در بخشی از اطلاعات بالا، عبارت 8way را مشاهده میکنیم. یعنی هر بلوک داده در هر دسته، به هشت خط کش مرتبط میشود. هرچه تعداد ارتباطها بیشتر باشد، شانس cache hit افزایش پیدا میکند. البته اضافه شدن تعداد خطوط، با بیشتر شدن پیچیدگی همراه خواهد بود و توان مصرفی را افزایش میدهد. ازطرفی کارایی و بهرهوری پردازنده هم دچار مشکل میشود، چون پردازنده باید برای هر بلوک داده، خطوط کش بیشتری را پردازش کند.
یکی دیگر از دلایل افزایش پیچیدگی کش، به چگونگی نگهداری و مدیریت داده در سطوح گوناگون مربوط میشود. قوانین مربوط به این فرایند در بخشی بهنام inclusion policy تنظیم میشوند. بهعنوان مثال، پردازندههای اینتل ساختار fully inclusive L1+L3 دارند. به بیان دیگر، دادههایی که در L1 هستند، امکان حضور در L3 را هم دارند. شاید در نگاه اول چنین ساختاری موجب هدر رفتن فضای کش باشد، اما مزیت اصلی در آنجا است که اگر پردازنده در پیدا کردن تگ داده در سطح پایینتر کش ناموفق بود، نیازی به جستوجو در سطح بالاتر نخواهد داشت. در همین پردازندها، بخش L2 دیگر شامل دادهها نمیشود. به بیان دیگر، دادههایی که در L2 هستند، در سطح دیگر کپی نمیشوند.
روند عدم کپی دادهها در L2 باعث صرفهجویی در فضای حافظه میشود، اما سیستم حافظهی تراشه مجبور میشود تا برای پیدا کردن یک تگ یافتنشده (missed tag) حافظهی بزرگتر L3 را جستوجو کند. رویکرد دیگری در معماری کش وجود دارد که بهنام Victim caches شناخته میشود و شبیه به روند بالا است. این نوع از کش برای ذخیرهسازی دادهی خارجشده از سطح پایینتر استفاده میشود. بهعنوان مثال، پردازندههای AMD Zen 2 از L3 victim cache استفاده میکنند که تنها دادههای کش L2 را ذخیره میکند.

در طراحی کش، ساختار و دستورالعمل مهم دیگری هم باید مدنظر قرار بگیرد. در این ساختار زمان ذخیرهی داده روی کش یا حافظهی اصلی سیستم، مشخص میشود. ساختار مذکور بهنام Write policies شناخته میشود که اکثر پردازندههای مدرن از سیاست موسوم به write-back بهره میبرند. به بیان دیگر وقتی داده روی یک سطح از حافظهی کش نوشته میشود، کمی تأخیر نیاز خواهد بود تا حافظهی اصلی با یک کپی از دادهی مذکور، بهروز شود. در اکثر از موارد، توقف در ارسال داده تا زمانیکه داده در کش باشد، ادامه پیدا میکند. تنها زمانیکه داده از کش خارج شود، حافظهی رم اطلاعات را دریافت میکند.
طراحان پردازنده، برای تصمیمگیری بین انتخابهای گوناگون مقدار، نوع و سیاستهای اجرایی کش، نیاز به ظرفیت بیشتر در پردازنده را با پیچیدگی بیشتر و فضای بیشتر قالب تراشه، در وضعیتی تعادلی بررسی میکنند. در یک دههی گذشته، پایینترین سطح حافظهی کش تغییر زیادی را تجربه نکرده است. درمقابل، ابعاد حافظهی L3 روند افزایشی را سپری کرد. ۱۰ سال پیش، برای خرید پردازندهای با ۱۲ مگابایت کش L3 باید هزینهای حدود هزار دلار پرداخت میشد. امروز با پرداخت هزینهای نصف، پردازنده با ۶۴ مگابایت حافظهی کش دراختیار کاربران قرار دارد.
چرا ظرفیت حافظهی کش CPU مدام در حال افزایش است؟
دلیل اینکه مدام ظرفیت حافظهی کش افزایش مییابد آن است که با افزایش حافظهی کش، شانس دسترسی به اطلاعات در این حافظه بیشتر شده و نیاز به رم کمتر میشود و این موضوع بهمعنی افزایش بازده سیستم خواهد بود.
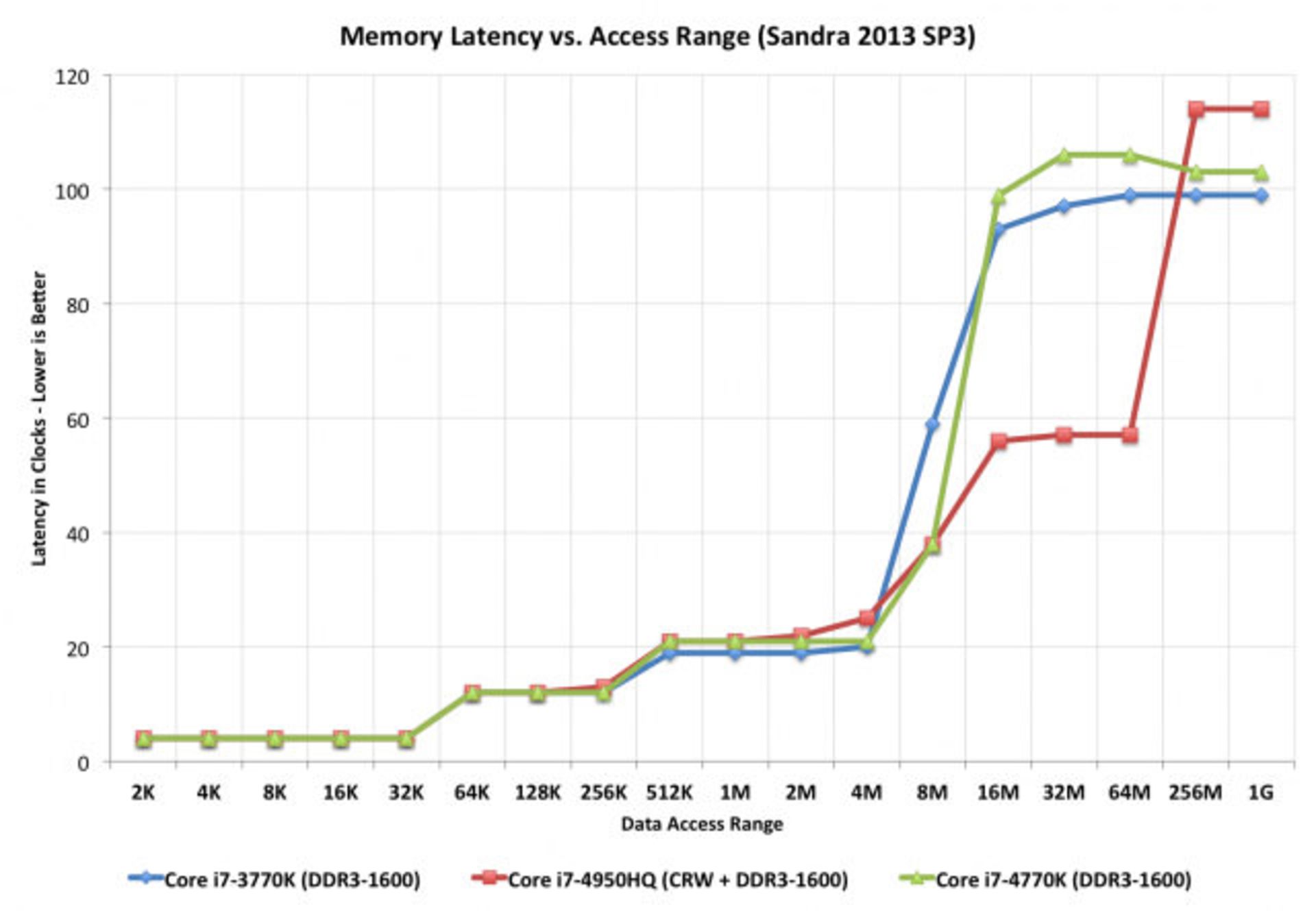
در نمودار بالا که از بررسی انندتک تهیه شده است میتوانید تأثیر اضافه شدن حافظهی ۱۲۸ مگابایتی L4 Cache را در کاهش تأخیر در هر کلاک مشاهده کنید. خط قرمز مربوط به پردازندهای است که حافظهی L4 دارد. دقت داشته باشید که برای فایلهای سنگین، سرعت آن تقریبا دو برابر دیگر پردازندههای اینتل است.
طراحی کش چه تأثیری روی بازده دارد؟
تأثیر اضافه شدن کش به CPU ارتباط مستقیم به نرخ مراجعات موفق پردازنده به کش دارد. هرچه دفعات مراجعهی CPU کمتر با شکست روبهرو شود، بازده پردازنده افزایش مییابد. در ادامه چند مثال برای این موضوع ارائه میکنیم تا دید بهتری نسبت به آن داشته باشید.
تصویر کنید که یک CPU مجبور باشد اطلاعات مشخصی را ۱۰۰ بار پشت سر هم از L1 بخواند. حافظهی L1 تأخیر یک نانوثانیه دارد و هر ۱۰۰ بار نیز حافظه با موفقیت اطلاعات را میخواند. به این ترتیب پردازنده ۱۰۰ نانوثانیه برای انجام این عملیات زمان صرف میکند.
حال تصور کنید که همان CPU با نرخ ۹۹ درصد اطلاعات را از L1 بخواند و صدمین مراجعهی آن به L1 بدون پاسخ بماند و مجبور باشد به L2 مراجعه کنید. تأخیر L2 ده سیکل یا ۱۰ نانوثانیه است به این ترتیب پردازنده ۹۹ نانوثانیه برای کسب اطلاعات از L1 و ۱۰ نانوثانیه برای کسب اطلاعات از L2 صرف میکند. این بدین معنی است که اگر یک درصد از مراجعات پردازنده به حافظهی L1 بدون پاسخ بماند ۱۰ درصد سرعت پردازنده کاهش مییابد.
در دنیای واقعی حافظهی L1 بین ۹۵ تا ۹۷ درصد مراجعات پردازنده را پاسخ میدهد، اما همان دو درصد اختلاف میتواند تأثیر محسوسی در سرعت پردازش امور داشته باشد. تازه این برای زمانی است که مطمئن باشیم اطلاعاتی که در L1 یافت نشده است حتما در L2 وجود دارد. اما در دنیای واقعی بعضی اوقات اطلاعات مورد نیاز پردازنده حتی در L3 و L4 نیز وجود ندارد و پردازنده مجبور به مراجعه به رم است. اگر پردازنده مجبور به کسب اطلاعات از رم باشد آنوقت سیکل پاسخدهی به ۸۰ تا ۱۲۰ نانوثانیه افزایش مییابد.
وقتی پردازندههای قدیمی سری بولدوزر AMD را با رقبای اینتلی آن مقایسه کنیم، مبحث طراحی کش و تأثیر آن روی بازده، به یک عامل بسیار مهم تبدیل میشود؛ عاملی که معادلات بازی را بر هم میزند. بسیاری از کارشناسان، یکی از دلایل مهم عقب ماندن AMD از Intel در سالهای گذشته در قدرت و بازدهی پردازندهها را طراحی کش میدانند.
پردازندههای سری بولدوزر AMD از مشکل Cache Contention رنج میبردند. این مشکل زمانی رخ میداد که دو رشته یا Thread متفاوت اطلاعات را روی یک سکتور از کش ذخیره میکردند. این مشکل تأثیر بسیار منفی روی بازده هر دو Thread داشت. تصور کنید که یک هسته برای کسب اطلاعات مدنظر خود به کش مراجعه میکند، اما هستهای دیگر اطلاعات مدنظر خود را روی همان بخش از حافظه کپی کرده است. در این صورت هسته مجبور است یک بار تمام سطوح کش را چک کرده و سپس به رم مراجعه کرده و مجددا اطلاعات مدنظر خود را در سطح اول کش بنویسد. این مشکل حتی در پردازندههای مجهز به معماری Streamroller AMD نیز وجود داشت و حتی تلاش این شرکت برای اختصاص ۹۶ کیلوبایت به L1 Code Cache هم مؤثر نبود. از طرفی حتی استفاده از فناوری HSA یا معماری ناهمگن نیز در این باره چندان مؤثر نبود. البته AMD با معرفی معماری Zen در سالهای اخیر سهم عمدهای از چالشها را برطرف کرد و حتی موفق به کسب سهم بازار بیشتر از اینتل شد.
به هر حال، کش مبحث فوقالعاده پیچیدهای است که در سرعت پردازش دستورها نقش مهمی را ایفا میکند و بهنظر میرسد مدیریت بهتر آن در پردازندههای اینتل یکی از مهمترین دلایل برتری محصولات این شرکت در رقابت با پردازندههای AMD بود.
مشخصات فنی کامل، قیمت پردازنده در فروشگاههای اینترنتی و مقایسهی کامل انواع CPU را در بخش محصولات مشاهده کنید؛ انواع CPU اینتل از جمله سری Core i3، Core i5 و Core i7 و انواع پردازنده AMD رایزن (Ryzen) برای مقایسه و خرید دردسترس کاربران است.

نظرات