
Мы начинаем публиковать лекции Натальи Васильевой, старшего научного сотрудника HP Labs и руководителя HP Labs Russia. Наталья Сергеевна читала курс, посвящённый анализу изображений, в петербургском Computer Science Center, который создан по совместной инициативе Школы анализа данных Яндекса, JetBrains и CS клуба
Всего в программе — девять лекций. В первой из них рассказывается о том, как применяется анализ изображений в медицине, системах безопасности и промышленности, какие задачи оно еще не научилось решать, какие преимущества имеет зрительное восприятие человека. Расшифровка этой части лекций — под катом. Начиная с 40-й минуты, лектор рассказывает об эксперименте Вебера, представлении и восприятии цвета, цветовой системе Манселла, цветовых пространствах и цифровых представлениях изображения. Полностью слайды лекции доступны по ссылке.
Изображения везде вокруг нас. Объёмы мультимедиа информации растут с каждой секундой. Снимаются фильмы, спортивные матчи, устанавливается аппаратура для видеонаблюдения. Мы сами каждый день снимаем большое количество фотографий и видео — такая возможность есть почти у каждого телефона.
Чтобы все эти изображения приносили пользу, нужно уметь что-то с ними делать. Можно сложить их в ящик, но тогда непонятно, для чего их создавать. Необходимо уметь искать нужные картинки, что-то делать с видеоданными — решать задачи, специфичные для той или иной области.
Наш курс называется «Анализ изображений и видео», но речь в основном будет идти об изображениях. Невозможно начать заниматься обработкой видео без знаний о том, что делать с картинкой. Видео — это набор статических изображений. Конечно, есть задачи, специфичные для видео. Например, слежение за объектами или выделение каких-то ключевых кадров. Но в основе всех алгоритмов работы с видео лежат алгоритмы обработки и анализа изображений.
Что же такое анализ изображений? Это во многом смежная и пересекающаяся с компьютерным зрением область. Точного и единственного определения у неё нет. Для примера приведем три.
В этом определении подразумевается, что вне зависимости от того, есть мы или нет, существует какой-то окружающий мир и его изображения, анализируя которые мы хотим что-то о нём понять. И это подходит не только для определения анализа цифровых изображений машиной, но и для их анализа нашей головой. У нас есть сенсор — глаза, у нас есть преобразующее устройство — мозг, и мы воспринимаем мир путем анализа тех картинок, которые видим.
Наверное, это больше относится к робототехнике. Мы хотим принимать решения и делать выводы о реальных объектах вокруг нас на основе изображений, которые уловили сенсоры. К примеру, это определение идеально подходит под описание того, что делает робот-пылесос. Он принимает решение о том, куда ему дальше ехать и какой угол пылесосить на основании того, что он видит.
Наиболее общее определение из трех. Если опираться на него, мы хотим просто описывать явления и объекты вокруг нас на основе анализа изображений.
Подытоживая, можно сказать, что в среднем анализ изображений сводится к извлечению значимой информации из изображений. Для каждой конкретной ситуации эта значимая информация может быть разной.
Если мы посмотрим на фотографию, на которой маленькая девочка ест мороженое, то сможем описать её словами, — так мозг интерпретирует то, что мы видим. Приблизительно этому мы хотим научить машину. Чтобы описать изображение текстом, необходимо провести такие операции, как распознавание объектов и лиц, определение пола и возраста человека, выделение однородных по цвету областей, распознавание действия, выделение текстуры.
В рамках курса мы будем говорить и об алгоритмах обработки изображений. Именно они используются, когда мы повышаем контрастность, удаляем цвет или шум, применяем фильтры и т.д… В принципе изменение картинок — это все, что делается в обработке изображений.
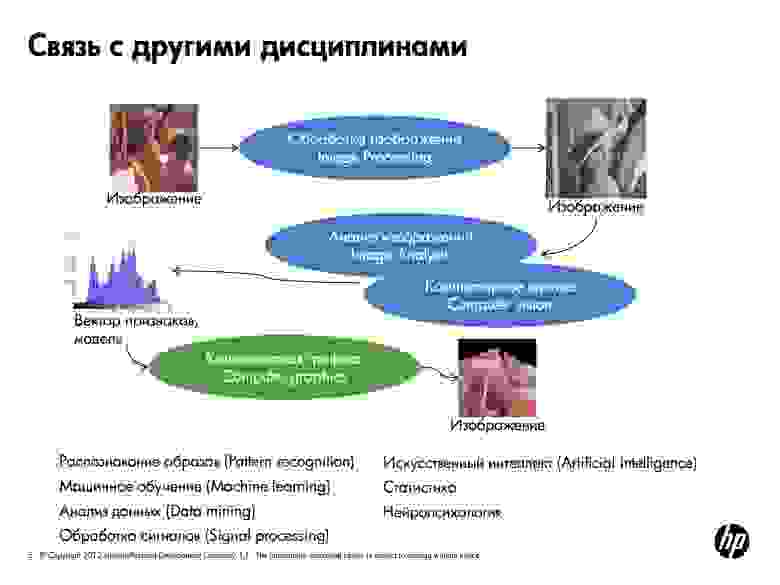
Далее идут анализ изображений и компьютерное зрение. Точных определений для них нет, но, на мой взгляд, для них характерно то, что имея на входе изображение, на выходе мы получаем некую модель или некоторый набор признаков. То есть некоторые числовые параметры, которые описывают это изображение. Например, гистограмма распределения уровней серого цвета.
В анализе изображений как результат мы получаем вектор признаков. Компьютерное зрение решает более широкие задачи. В частности строятся модели. К примеру, по набору двухмерных изображений можно построить трехмерную модель помещений. И есть еще одна смежная область — компьютерная графика, в которой генерируют изображение по модели.
Все это невозможно без использования знаний и алгоритмов из еще целого ряда областей. Таких, как распознавание образов и машинное обучение. В принципе можно сказать, что анализ изображений — это частный случай анализа данных, область искусственного интеллекта. К смежной дисциплине можно отнести и нейропсихологию — для того чтобы понять, какие у нас есть возможности и как устроено восприятие картинок, хорошо бы понимать, как эти задачи решает наш мозг.
Существуют огромные архивы и коллекции изображений, и одной из самых главных задач является индексирование и поиск картинок. Коллекции бывают разные:
Что можно делать со всеми этими картинками? Самое простое — можно как-то по-умному построить навигацию по ним, классифицируя их по темам. Отдельно складывать мишек, отдельно слонов, отдельно апельсины — так, чтобы пользователю потом было удобно навигировать по этой коллекции.
Отдельная задача — это поиск дубликатов. В двух тысячах фотографий из отпуска неповторяющихся не так уж и много. Мы любим экспериментировать, снимать с разной выдержкой, фокусным расстоянием и т.д., что в итоге нам дает большое количество нечетких дубликатов. Кроме того, поиск по дубликатам может помочь обнаружить незаконное использование вашей фотографии, которую вы однажды могли выложить в интернете.
Отличная задача — выбор лучшей фотографии. С помощью алгоритма можно понять, какая картинка больше всего понравится пользователю. Например, если это портрет, лицо должно быть освещено, глаза открыты, изображение должно быть четким и т.д. В современных фотоаппаратах уже есть такая функция.
Тоже задача поиска — создание коллажей, т.е. подбор фотографий, которые будут хорошо смотреться рядом.
Сейчас совершенно потрясающие вещи происходят в медицине.
Еще одна область применения – это системы безопасности. Кроме использования отпечатков пальцев и сетчатки глаза для авторизации, здесь есть и не решенные пока задачи. Например, **обнаружение «подозрительных» предметов**. Её сложность в том, что вы не можете заранее дать описание того, что является подозрительным предметом. Другая интересная задача — **выявление подозрительного поведения** человека в системах видеонаблюдения. Невозможно предоставить все возможные примеры аномального поведения, поэтому распознавание будет устроено на выявлении отклонений от того, что помечено как нормальное.

Есть еще большое количество областей, где используется анализ изображений: военная промышленность, робототехника, кинопроизводство, создание компьютерных игр, автомобилестроение. В 2010 году одна итальянская компания оснастила камерами грузовик, который, используя карты и сигнал GPS, на автоматическом управлении проехал от Италии до Шанхая. Путь проходил и через Сибирь, не все дороги которой есть на картах. На этом отрезке карту ему передавал управляемый человеком автомобиль, который ехал перед ним. Грузовик же сам распознавал дорожные знаки, пешеходов и понимал, как ему можно перестраиваться.
Но почему мы до сих пор водим автомобили самостоятельно, и даже к системам видеонаблюдения должен быть приставлен человек? Одна из ключевых проблем — семантический разрыв.
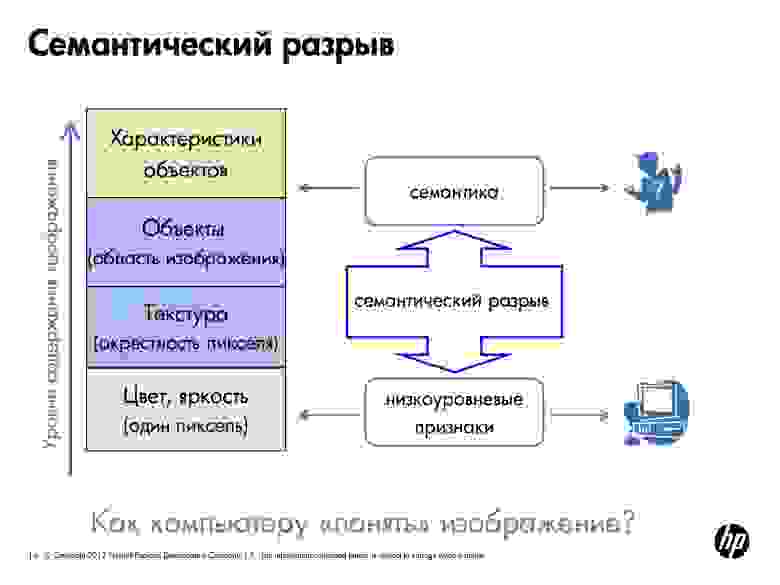
Человек, глядя на картинку, понимает её семантику. Компьютер же понимает цвет пикселей, умеет выделить текстуру и в конечном счете отличить кирпичную стену от ковра и распознать на фотографии человека, но определить, счастлив ли он, машина ещё может. Мы сами не всегда можем это понять. То есть автоматическое понимание того, скучают ли студенты на лекции, — это следующий уровень.
Кроме того, наш мозг — это уникальная система понимания и обработки той картинки, которую мы видим. Он склонен видеть то, что мы хотим видеть, а как научить такому же компьютер — открытый вопрос.

Мы очень хорошо умеем обобщать. По изображению мы способны догадаться, что видим лампу. Нам не нужно знать все модификации предмета из одного класса, чтобы отнести к нему образец. Компьютеру это сделать сложнее, потому что визуально разные лампы могут сильно отличаться.
Есть еще ряд сложностей, с которыми анализ изображений еще не справился.

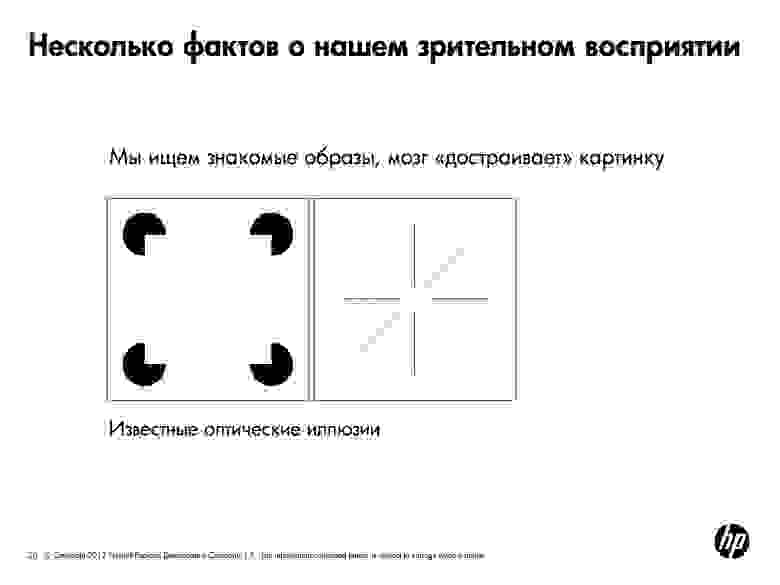
Наш мозг часто «достраивает» картинку и добавляет семантику. Мы все можем увидеть «что-то» или «кого-то» в очертании облака. Зрительная система самообучается. Европейцу сложно различать лица азиатов, так как обычно в жизни он редко их встречает. Зрительная система научилась улавливать различия в европейских лицах, а азиаты, которых он видел мало, кажутся ему «на одно лицо». И наоборот. Был случай с коллегами из Пало-Альто, которые совместно с китайцами разрабатывали алгоритм обнаружения лиц. В итоге он чудесно находил азиатов, но не мог увидеть европейцев.
В каждой картинке мы в первую очередь ищем знакомые образы. Например, мы здесь видим квадраты и круги.

Глаз способен воспринимать очень большие диапазоны яркости, но делает это хитрым образом. Зрительная система адаптируется к диапазону значений яркости порядка 10^10. Но в каждый конкретный момент мы можем распознать небольшой участок яркости. То есть наш глаз выбирает себе какую-то точку, адаптируется к значению яркости в ней и распознает только небольшой диапазон вокруг этой точки. Все то, что темнее, кажется черным, все то, что светлее — белым. Но глаз очень быстро перемещается и мозг достраивает картинку, поэтому мы видим хорошо.
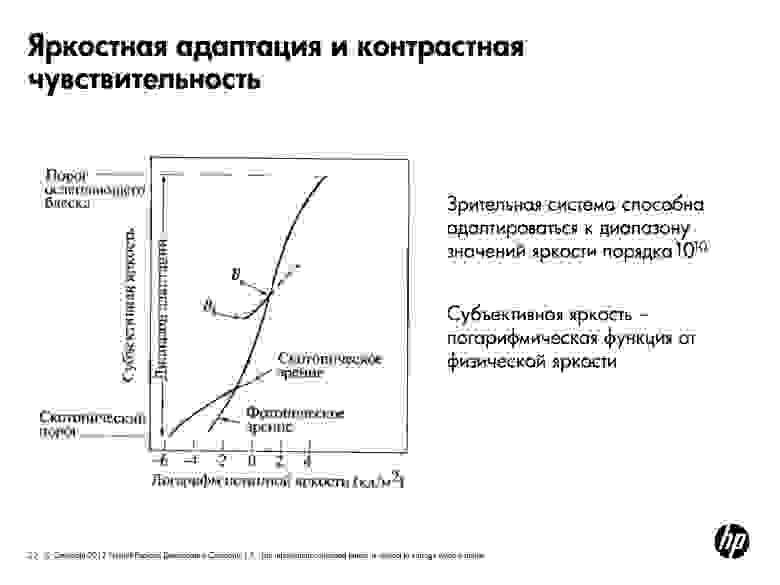
Субъективная яркость – логарифм от физической яркости. Если мы посмотрим на изменение яркости какого-либо источника и станем изменять яркость линейно, наш глаз будет воспринимать ее как логарифм.

За зрительное восприятие отвечают два типа компонентов — колбочки и палочки. Колбочки отвечают за цветовое восприятие и могут очень четко воспринять картинку, но в том случае, если не очень темно. Это называется фотопическим зрением. В темноте работает скотопическое зрение — включаются палочки, которых меньше колбочек и которые не воспринимают цвет, поэтому картинка получается размытой.
Всего в программе — девять лекций. В первой из них рассказывается о том, как применяется анализ изображений в медицине, системах безопасности и промышленности, какие задачи оно еще не научилось решать, какие преимущества имеет зрительное восприятие человека. Расшифровка этой части лекций — под катом. Начиная с 40-й минуты, лектор рассказывает об эксперименте Вебера, представлении и восприятии цвета, цветовой системе Манселла, цветовых пространствах и цифровых представлениях изображения. Полностью слайды лекции доступны по ссылке.
Изображения везде вокруг нас. Объёмы мультимедиа информации растут с каждой секундой. Снимаются фильмы, спортивные матчи, устанавливается аппаратура для видеонаблюдения. Мы сами каждый день снимаем большое количество фотографий и видео — такая возможность есть почти у каждого телефона.
Чтобы все эти изображения приносили пользу, нужно уметь что-то с ними делать. Можно сложить их в ящик, но тогда непонятно, для чего их создавать. Необходимо уметь искать нужные картинки, что-то делать с видеоданными — решать задачи, специфичные для той или иной области.
Наш курс называется «Анализ изображений и видео», но речь в основном будет идти об изображениях. Невозможно начать заниматься обработкой видео без знаний о том, что делать с картинкой. Видео — это набор статических изображений. Конечно, есть задачи, специфичные для видео. Например, слежение за объектами или выделение каких-то ключевых кадров. Но в основе всех алгоритмов работы с видео лежат алгоритмы обработки и анализа изображений.
Что же такое анализ изображений? Это во многом смежная и пересекающаяся с компьютерным зрением область. Точного и единственного определения у неё нет. Для примера приведем три.
Computing properties of the 3D world from one or more digital images. Trucco and Veri
В этом определении подразумевается, что вне зависимости от того, есть мы или нет, существует какой-то окружающий мир и его изображения, анализируя которые мы хотим что-то о нём понять. И это подходит не только для определения анализа цифровых изображений машиной, но и для их анализа нашей головой. У нас есть сенсор — глаза, у нас есть преобразующее устройство — мозг, и мы воспринимаем мир путем анализа тех картинок, которые видим.
Make useful decision about real physical objects and scenes based on the sensed images. Shapiro
Наверное, это больше относится к робототехнике. Мы хотим принимать решения и делать выводы о реальных объектах вокруг нас на основе изображений, которые уловили сенсоры. К примеру, это определение идеально подходит под описание того, что делает робот-пылесос. Он принимает решение о том, куда ему дальше ехать и какой угол пылесосить на основании того, что он видит.
The construction of explicit, meaningful decisions of physical objects from images
Наиболее общее определение из трех. Если опираться на него, мы хотим просто описывать явления и объекты вокруг нас на основе анализа изображений.
Подытоживая, можно сказать, что в среднем анализ изображений сводится к извлечению значимой информации из изображений. Для каждой конкретной ситуации эта значимая информация может быть разной.
Если мы посмотрим на фотографию, на которой маленькая девочка ест мороженое, то сможем описать её словами, — так мозг интерпретирует то, что мы видим. Приблизительно этому мы хотим научить машину. Чтобы описать изображение текстом, необходимо провести такие операции, как распознавание объектов и лиц, определение пола и возраста человека, выделение однородных по цвету областей, распознавание действия, выделение текстуры.
Связь с другими дисциплинами
В рамках курса мы будем говорить и об алгоритмах обработки изображений. Именно они используются, когда мы повышаем контрастность, удаляем цвет или шум, применяем фильтры и т.д… В принципе изменение картинок — это все, что делается в обработке изображений.

Далее идут анализ изображений и компьютерное зрение. Точных определений для них нет, но, на мой взгляд, для них характерно то, что имея на входе изображение, на выходе мы получаем некую модель или некоторый набор признаков. То есть некоторые числовые параметры, которые описывают это изображение. Например, гистограмма распределения уровней серого цвета.
В анализе изображений как результат мы получаем вектор признаков. Компьютерное зрение решает более широкие задачи. В частности строятся модели. К примеру, по набору двухмерных изображений можно построить трехмерную модель помещений. И есть еще одна смежная область — компьютерная графика, в которой генерируют изображение по модели.
Все это невозможно без использования знаний и алгоритмов из еще целого ряда областей. Таких, как распознавание образов и машинное обучение. В принципе можно сказать, что анализ изображений — это частный случай анализа данных, область искусственного интеллекта. К смежной дисциплине можно отнести и нейропсихологию — для того чтобы понять, какие у нас есть возможности и как устроено восприятие картинок, хорошо бы понимать, как эти задачи решает наш мозг.
Для чего нужен анализ изображений
Существуют огромные архивы и коллекции изображений, и одной из самых главных задач является индексирование и поиск картинок. Коллекции бывают разные:
- Персональные. Например, в отпуске человек может сделать пару тысяч фотографий, с которыми потом нужно что-то делать.
- Профессиональные. Они насчитывают миллионы фотографий. Здесь тоже есть необходимость как-то их организовывать, искать, находить то, что требуется.
- Коллекции репродукций. Это тоже миллионы изображений. Сейчас у большого количества музеев есть виртуальные версии, для которых оцифровываются репродукции, т.е. мы получаем изображения картин. Пока утопичная задача — поиск всех репродукций одного и того же автора. Человек по стилю может предположить, что видит, допустим, картины Сальвадора Дали. Было бы здорово, если бы этому научилась и машина.
Что можно делать со всеми этими картинками? Самое простое — можно как-то по-умному построить навигацию по ним, классифицируя их по темам. Отдельно складывать мишек, отдельно слонов, отдельно апельсины — так, чтобы пользователю потом было удобно навигировать по этой коллекции.
Отдельная задача — это поиск дубликатов. В двух тысячах фотографий из отпуска неповторяющихся не так уж и много. Мы любим экспериментировать, снимать с разной выдержкой, фокусным расстоянием и т.д., что в итоге нам дает большое количество нечетких дубликатов. Кроме того, поиск по дубликатам может помочь обнаружить незаконное использование вашей фотографии, которую вы однажды могли выложить в интернете.
Отличная задача — выбор лучшей фотографии. С помощью алгоритма можно понять, какая картинка больше всего понравится пользователю. Например, если это портрет, лицо должно быть освещено, глаза открыты, изображение должно быть четким и т.д. В современных фотоаппаратах уже есть такая функция.
Тоже задача поиска — создание коллажей, т.е. подбор фотографий, которые будут хорошо смотреться рядом.
Применение алгоритмов анализа изображений
Сейчас совершенно потрясающие вещи происходят в медицине.
- Выявление аномалий. Уже широко известная и решаемая проблема. К примеру, по рентгеновскому снимку пытаются понять, здоров пациент или нет — отличается ли этот снимок от снимка здорового человека. Это может быть как снимок всего тела, так и отдельно кровеносной системы, чтобы выделить из нее аномальные сосуды. В рамках этой задачи — поиск раковых клеток.
- Диагностика заболеваний. Также делается на основе снимков. Если у вас есть база снимков пациентов и известно, что первая аномалия встречается у здоровых людей, а вторая означает, что человек болен раком, то, основываясь на подобии изображений, можно помочь врачам с диагностикой заболеваний.
- Моделирование организма и предсказание последствий лечения. Сейчас это то, что называется, cutting edge. Хотя мы все и похожи, каждый организм устроен индивидуально. Наример, у нас может быть разное расположение или толщина кровеносных сосудов. Если человеку требуется соединить разорванный сосуд шунтом, то определить, где его ставить, можно, основываясь на экспертном мнении врача, а можно — смоделировав по снимку кровеносную систему и «вставив» шунт в этой модели. Так мы получим возможность увидеть, как изменится кровоток, и предсказать, как пациент будет себя чувствовать при разных вариантах.
Еще одна область применения – это системы безопасности. Кроме использования отпечатков пальцев и сетчатки глаза для авторизации, здесь есть и не решенные пока задачи. Например, **обнаружение «подозрительных» предметов**. Её сложность в том, что вы не можете заранее дать описание того, что является подозрительным предметом. Другая интересная задача — **выявление подозрительного поведения** человека в системах видеонаблюдения. Невозможно предоставить все возможные примеры аномального поведения, поэтому распознавание будет устроено на выявлении отклонений от того, что помечено как нормальное.

Есть еще большое количество областей, где используется анализ изображений: военная промышленность, робототехника, кинопроизводство, создание компьютерных игр, автомобилестроение. В 2010 году одна итальянская компания оснастила камерами грузовик, который, используя карты и сигнал GPS, на автоматическом управлении проехал от Италии до Шанхая. Путь проходил и через Сибирь, не все дороги которой есть на картах. На этом отрезке карту ему передавал управляемый человеком автомобиль, который ехал перед ним. Грузовик же сам распознавал дорожные знаки, пешеходов и понимал, как ему можно перестраиваться.
Сложности
Но почему мы до сих пор водим автомобили самостоятельно, и даже к системам видеонаблюдения должен быть приставлен человек? Одна из ключевых проблем — семантический разрыв.

Человек, глядя на картинку, понимает её семантику. Компьютер же понимает цвет пикселей, умеет выделить текстуру и в конечном счете отличить кирпичную стену от ковра и распознать на фотографии человека, но определить, счастлив ли он, машина ещё может. Мы сами не всегда можем это понять. То есть автоматическое понимание того, скучают ли студенты на лекции, — это следующий уровень.
Кроме того, наш мозг — это уникальная система понимания и обработки той картинки, которую мы видим. Он склонен видеть то, что мы хотим видеть, а как научить такому же компьютер — открытый вопрос.

Мы очень хорошо умеем обобщать. По изображению мы способны догадаться, что видим лампу. Нам не нужно знать все модификации предмета из одного класса, чтобы отнести к нему образец. Компьютеру это сделать сложнее, потому что визуально разные лампы могут сильно отличаться.
Есть еще ряд сложностей, с которыми анализ изображений еще не справился.

Зрительное восприятие человека
Наш мозг часто «достраивает» картинку и добавляет семантику. Мы все можем увидеть «что-то» или «кого-то» в очертании облака. Зрительная система самообучается. Европейцу сложно различать лица азиатов, так как обычно в жизни он редко их встречает. Зрительная система научилась улавливать различия в европейских лицах, а азиаты, которых он видел мало, кажутся ему «на одно лицо». И наоборот. Был случай с коллегами из Пало-Альто, которые совместно с китайцами разрабатывали алгоритм обнаружения лиц. В итоге он чудесно находил азиатов, но не мог увидеть европейцев.
В каждой картинке мы в первую очередь ищем знакомые образы. Например, мы здесь видим квадраты и круги.


Глаз способен воспринимать очень большие диапазоны яркости, но делает это хитрым образом. Зрительная система адаптируется к диапазону значений яркости порядка 10^10. Но в каждый конкретный момент мы можем распознать небольшой участок яркости. То есть наш глаз выбирает себе какую-то точку, адаптируется к значению яркости в ней и распознает только небольшой диапазон вокруг этой точки. Все то, что темнее, кажется черным, все то, что светлее — белым. Но глаз очень быстро перемещается и мозг достраивает картинку, поэтому мы видим хорошо.

Субъективная яркость – логарифм от физической яркости. Если мы посмотрим на изменение яркости какого-либо источника и станем изменять яркость линейно, наш глаз будет воспринимать ее как логарифм.
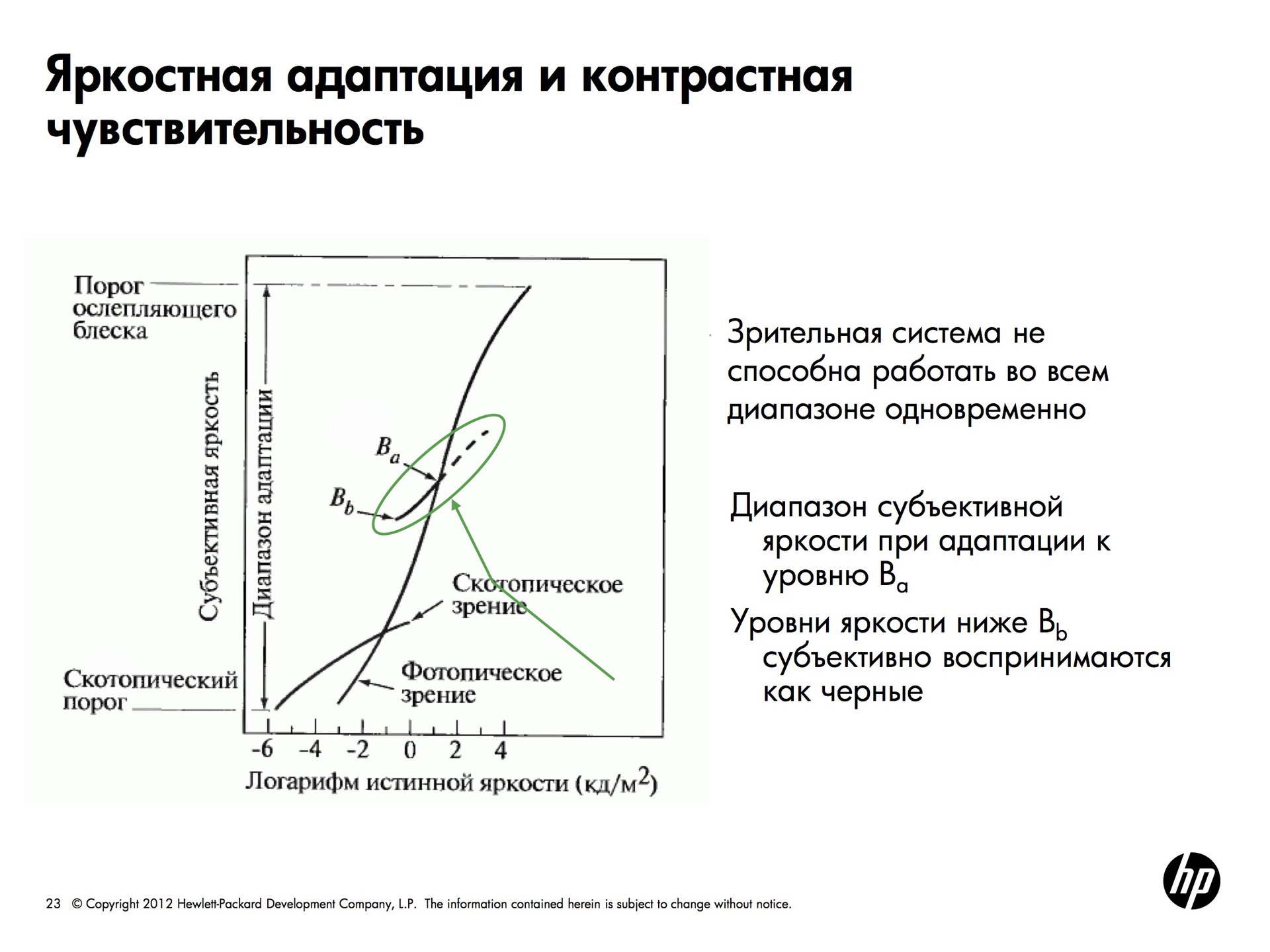
За зрительное восприятие отвечают два типа компонентов — колбочки и палочки. Колбочки отвечают за цветовое восприятие и могут очень четко воспринять картинку, но в том случае, если не очень темно. Это называется фотопическим зрением. В темноте работает скотопическое зрение — включаются палочки, которых меньше колбочек и которые не воспринимают цвет, поэтому картинка получается размытой.
