
Некоторое время назад мы рассказывали на Хабре о том, что поиск Яндекса стал более персонализированным. Он учитывает не только постоянные, но и сиюминутные интересы пользователя, ориентируясь на последние несколько запросов и действий.
Сегодня мы хотим рассказать о технологии Real Time MapReduce, благодаря которой всё это стало возможно. Она обеспечивает передачу и обработку огромных объёмов данных, необходимых для этой задачи, и чтобы сделать это, нам даже не пришлось переписывать код для MapReduce, который у нас уже использовался.

Чтобы персонализировать поисковую выдачу, нужно определить круг интересов пользователя, для чего мы сохраняем информацию о его поведении на странице поиска. Данные о действиях пользователя записываются в логи, а затем обрабатываются при помощи специальных алгоритмов, которые позволяют нам составить наиболее релевантную выдачу по запросу для каждого отдельно взятого пользователя. Сначала обработка логов запускалась раз в сутки, для чего очень хорошо подходила технология распределенных вычислений MapReduce. Она прекрасно справляется с анализом значительных объемов данных.
Входящие данные (в нашем случае это логи) проходят через несколько последовательных шагов Map (данные разбиваются по ключам) и Reduce (происходят вычисления по определенной функции и собирается результат). При этом результат вычислений, происходящих на каждом этапе, одновременно является входящими данными для следующего этапа. Путем прогона через специальные алгоритмы на каждом Reduce-шаге объем данных сокращается. В результате из огромного объема сырых данных мы получаем небольшое количество полезных.
Однако, как уже говорилось в предыдущих постах, у пользователей есть не только постоянные, но и сиюминутные интересы, которые могут сменяться буквально за секунды. И тут данные суточной давности ничем помочь уже не могут. Мы могли бы ускорить этот процесс до получаса, некоторые логи обрабатываются именно с такой периодичностью, но наша задача требует мгновенной реакции. К сожалению, при использовании MapReduce существует вполне определенный потолок реактивности, обусловленный характером обработки.
Этапы обработки производятся в строгой очередности (ведь каждый этап генерирует данные, которые будут обрабатываться на следующих), и для получения финального результата по одному ключу нужно дождаться окончания всей обработки. Даже при незначительных изменениях во входящих данных всю цепочку этапов необходимо проводить заново, так как без пересчета невозможно определить, на какие из промежуточных результатов окажут влияние эти изменения. При постоянном потоке поступающих данных (а с наших поисковых машин идет поток со скоростью около 200 Мбайт/с) такая система эффективно работать неспособна, и добиться реакции на действия пользователя за несколько секунд этим методом невозможно.
Нам же нужна система, которая могла бы при мелких изменениях входящих данных быстро изменять окончательный результат. Для этого она должна уметь определять, какие ключи будут модифицированы в результате изменений, и проводить пересчет только для них. Таким образом, объем обрабатываемых на каждом этапе данных сократится, а вместе с тем увеличится и скорость обработки.
В Яндексе есть несколько проектов, применяющих классические кластерные приложения, где данные разбиваются по нодам, между которыми происходит обмен сообщениями, позволяющими изменять состояния для отдельных ключей, не производя полного пересчета. Однако для сложных вычислений, которые подразумевает обработка логов, такая модель не подходит из-за слишком большой нагрузки на обработчик сообщений.
Кроме того, большая часть накопившегося у нас кода, обеспечивающего качество поиска, написана под MapReduce. И почти весь этот код с небольшими модификациями можно было бы использовать повторно для обработки действий пользователя в реальном времени. Так и родилась идея создать систему c API, идентичным интерфейсу MapReduce, но при этом способную самостоятельно распознавать ключи, затрагиваемые изменениями входящих данных.
Изначально замысел казался достаточно простым: нужно было сделать архитектуру, которая умеет вычислять MapReduce-функции, но также может за секунды инкрементально и эффективно обновлять значение функций при небольших изменениях входных данных. Первый прототип RealTime MapReduce (RTMR) был готов уже через две недели. Однако в процессе тестирования стали открываться слабые места.
По отдельности все проблемы казались пустяковыми, но в системах такого масштаба увязать все друг с другом не так просто. В итоге после устранения всех проблем от изначального прототипа не осталось практически ничего, а объем кода вырос на порядок.
Кроме того, стало ясно, что для обеспечения необходимой скорости работы все данные, участвующие в расчетах, необходимо хранить в памяти, для чего мы реализовали специальную архитектуру.
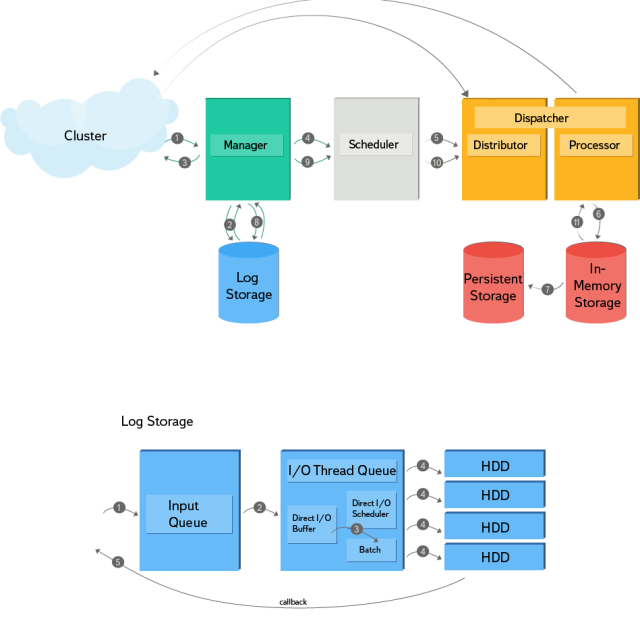
Разберем подробнее последовательность действий, отображенную на схеме:
Вторая часть схемы демонстрирует принцип работы хранилища логов. Оно поддерживает асинхронную запись с входящей очередью, а также callback для нотификаций. На диске реализована append-only структура и индекс для фильтрации записей по ключу. Адаптивный планировщик использует статистику read-операций для определения размера записи, находя оптимальный баланс между скоростью записи и временем ожидания перед ее началом. Хранилище логов состоит из четырех HDD без RAID с шардированием по ключу. Для записи данных на диски используется Direct I/O.
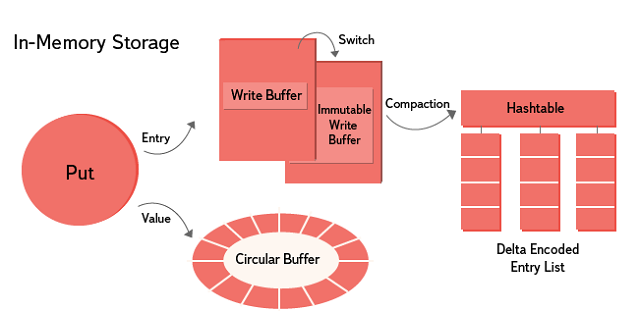
В in-memory storage реализован подход с последовательной записью и параллельным чтением. Шардирование осуществляется по ключу. Данные хранятся на протяжении определенного в настройках промежутка времени, по истечении которого могут быть перезаписаны новыми. Для хранения value-данных применяется lock-free кольцевой буфер. Для записей (key, subkey, table, timestamp + дополнительная информация) используется append-only lock-free Skip List. После заполнения Skip List создается новый, а старый объединяется с имеющимися immutable-данными. Для каждого ключа записи сортируются и дельта-кодируются.
Координация узлов в кластере осуществляется при помощи Zookeeper. Определение мастера/слейва производится через consistent hashing. Исходящие транзакции обрабатываются мастером и дополнительно сохраняются на слейвах. Срезы также размещаются как на мастере, так и на слейвах. При перешардировании новый мастер собирает данные из среза на кластере, а также необработанные транзакции из лога по своему диапазону ключей, догоняет свое состояние и включается в обработку.
Стоит отметить, что кроме персонализации поиска для RTMR можно найти и другие применения. В большинстве случаев применяемые в Поиске алгоритмы можно перестроить на работу в режиме реального времени. Например, с его помощью можно улучшить качество поиска по свежим документам, публикациям в СМИ и блогах. Ведь ранжирование свежих документов зависит не только от скорости их обхода и индексации, это не самый сложный процесс и в большинстве случаев наш робот уже достаточно давно справляется с этим за несколько секунд. Однако значительная часть данных для ранжирования берется из внешних по отношению к документу источников информации, и для агрегации этих данных используется MapReduce. Как уже говорилось выше, ограничения методов батч-обработки не позволяют производить агрегацию быстрее, чем за 20-30 минут. Поэтому без RTMR часть внешних сигналов для свежих документов приходит с запаздыванием.
Подстройку поисковых подсказок тоже можно сделать моментальной. Тогда предлагаемые пользователю варианты запроса будут зависеть от того, что он искал несколько секунд назад.
Так как наша система еще достаточно молода, в ближайших планах у нас расширение парадигмы MapReduce: добавление в нее новых интерфейсов, заточенных специально под работу в реальном времени. Например, операций, способных способных делать предварительную неполную предагрегацию.
Кроме того, мы планируем произвести унифицированное для MapReduce и RTMR декларативное описание потоков данных и графа вычислений. Стадии RTMR-вычислений для разных ключей в отличие от MapReduce работают непоследовательно, а значит, последовательный запуск стадий из кода теряет всякий смысл.
Сегодня мы хотим рассказать о технологии Real Time MapReduce, благодаря которой всё это стало возможно. Она обеспечивает передачу и обработку огромных объёмов данных, необходимых для этой задачи, и чтобы сделать это, нам даже не пришлось переписывать код для MapReduce, который у нас уже использовался.

Чтобы персонализировать поисковую выдачу, нужно определить круг интересов пользователя, для чего мы сохраняем информацию о его поведении на странице поиска. Данные о действиях пользователя записываются в логи, а затем обрабатываются при помощи специальных алгоритмов, которые позволяют нам составить наиболее релевантную выдачу по запросу для каждого отдельно взятого пользователя. Сначала обработка логов запускалась раз в сутки, для чего очень хорошо подходила технология распределенных вычислений MapReduce. Она прекрасно справляется с анализом значительных объемов данных.
Входящие данные (в нашем случае это логи) проходят через несколько последовательных шагов Map (данные разбиваются по ключам) и Reduce (происходят вычисления по определенной функции и собирается результат). При этом результат вычислений, происходящих на каждом этапе, одновременно является входящими данными для следующего этапа. Путем прогона через специальные алгоритмы на каждом Reduce-шаге объем данных сокращается. В результате из огромного объема сырых данных мы получаем небольшое количество полезных.
Однако, как уже говорилось в предыдущих постах, у пользователей есть не только постоянные, но и сиюминутные интересы, которые могут сменяться буквально за секунды. И тут данные суточной давности ничем помочь уже не могут. Мы могли бы ускорить этот процесс до получаса, некоторые логи обрабатываются именно с такой периодичностью, но наша задача требует мгновенной реакции. К сожалению, при использовании MapReduce существует вполне определенный потолок реактивности, обусловленный характером обработки.
Этапы обработки производятся в строгой очередности (ведь каждый этап генерирует данные, которые будут обрабатываться на следующих), и для получения финального результата по одному ключу нужно дождаться окончания всей обработки. Даже при незначительных изменениях во входящих данных всю цепочку этапов необходимо проводить заново, так как без пересчета невозможно определить, на какие из промежуточных результатов окажут влияние эти изменения. При постоянном потоке поступающих данных (а с наших поисковых машин идет поток со скоростью около 200 Мбайт/с) такая система эффективно работать неспособна, и добиться реакции на действия пользователя за несколько секунд этим методом невозможно.
Нам же нужна система, которая могла бы при мелких изменениях входящих данных быстро изменять окончательный результат. Для этого она должна уметь определять, какие ключи будут модифицированы в результате изменений, и проводить пересчет только для них. Таким образом, объем обрабатываемых на каждом этапе данных сократится, а вместе с тем увеличится и скорость обработки.
В Яндексе есть несколько проектов, применяющих классические кластерные приложения, где данные разбиваются по нодам, между которыми происходит обмен сообщениями, позволяющими изменять состояния для отдельных ключей, не производя полного пересчета. Однако для сложных вычислений, которые подразумевает обработка логов, такая модель не подходит из-за слишком большой нагрузки на обработчик сообщений.
Кроме того, большая часть накопившегося у нас кода, обеспечивающего качество поиска, написана под MapReduce. И почти весь этот код с небольшими модификациями можно было бы использовать повторно для обработки действий пользователя в реальном времени. Так и родилась идея создать систему c API, идентичным интерфейсу MapReduce, но при этом способную самостоятельно распознавать ключи, затрагиваемые изменениями входящих данных.
Архитектура
Изначально замысел казался достаточно простым: нужно было сделать архитектуру, которая умеет вычислять MapReduce-функции, но также может за секунды инкрементально и эффективно обновлять значение функций при небольших изменениях входных данных. Первый прототип RealTime MapReduce (RTMR) был готов уже через две недели. Однако в процессе тестирования стали открываться слабые места.
По отдельности все проблемы казались пустяковыми, но в системах такого масштаба увязать все друг с другом не так просто. В итоге после устранения всех проблем от изначального прототипа не осталось практически ничего, а объем кода вырос на порядок.
Кроме того, стало ясно, что для обеспечения необходимой скорости работы все данные, участвующие в расчетах, необходимо хранить в памяти, для чего мы реализовали специальную архитектуру.
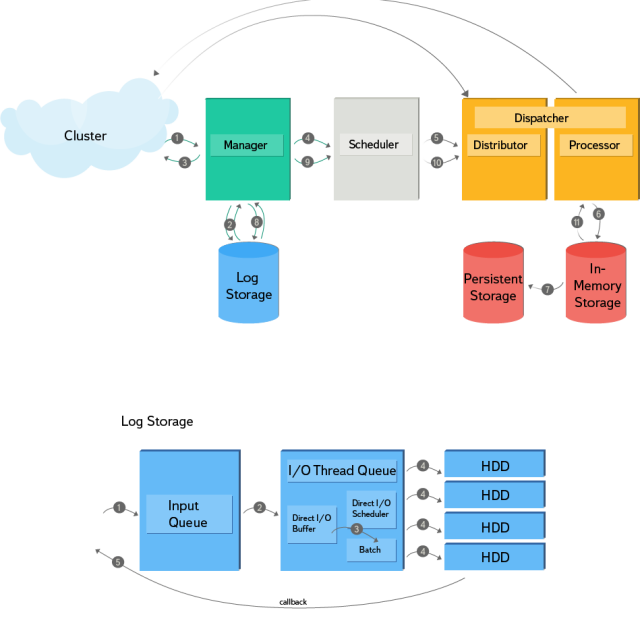
Разберем подробнее последовательность действий, отображенную на схеме:
- Начинается все с того, что обработчик входящего запроса разбирает данные и запускает отдельную транзакцию для каждого ключа.
- При этом транзакция считается запущенной только после получения подтверждения, что запись о начале операции (PrepareRecord) сохранена на диске.
- После запуска транзакции по сети отправляется ответ на входящий запрос, а транзакция ставится в очередь на обработку рабочим потоком.
- Далее рабочий поток подхватывает транзакцию и в зависимости от локальности ключа либо отправляет его по сети и ждет подтверждения, либо создает контент обработки, в котором выполняются операции.
- В дальнейшем транзакции обрабатываются изолированно друг от друга: после старта от общего состояния системы отводится бранч, по окончании обработки изменения принимаются.
- Все данные хранятся в памяти, что крайне важно для оптимизации reduce-операций.
- Данные по модифицированным ключам периодически сохраняются в постоянное хранилище в качестве резервных копий.
- После обработки транзакции ее результат фиксируется на диске, и при получении подтверждения записи от лога она считается завершенной.
- Также транзакция может порождать дочерние транзакции, в этом случае все повторяется, начиная с четвертого пункта.
- В процессе восстановления состояния данные извлекаются из постоянного хранилища и воспроизводятся по логу, незавершенные транзакции при этом перезапускаются. Если же возникает необходимость прервать транзакцию, в лог записывается AbortRecord (индикатор того, что при восстановлении состояния эту транзакцию перезапускать не нужно).
Вторая часть схемы демонстрирует принцип работы хранилища логов. Оно поддерживает асинхронную запись с входящей очередью, а также callback для нотификаций. На диске реализована append-only структура и индекс для фильтрации записей по ключу. Адаптивный планировщик использует статистику read-операций для определения размера записи, находя оптимальный баланс между скоростью записи и временем ожидания перед ее началом. Хранилище логов состоит из четырех HDD без RAID с шардированием по ключу. Для записи данных на диски используется Direct I/O.
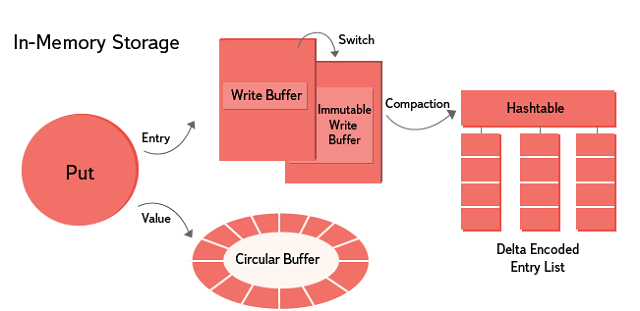
В in-memory storage реализован подход с последовательной записью и параллельным чтением. Шардирование осуществляется по ключу. Данные хранятся на протяжении определенного в настройках промежутка времени, по истечении которого могут быть перезаписаны новыми. Для хранения value-данных применяется lock-free кольцевой буфер. Для записей (key, subkey, table, timestamp + дополнительная информация) используется append-only lock-free Skip List. После заполнения Skip List создается новый, а старый объединяется с имеющимися immutable-данными. Для каждого ключа записи сортируются и дельта-кодируются.
Координация узлов в кластере осуществляется при помощи Zookeeper. Определение мастера/слейва производится через consistent hashing. Исходящие транзакции обрабатываются мастером и дополнительно сохраняются на слейвах. Срезы также размещаются как на мастере, так и на слейвах. При перешардировании новый мастер собирает данные из среза на кластере, а также необработанные транзакции из лога по своему диапазону ключей, догоняет свое состояние и включается в обработку.
Перспективы RealTime MapReduce
Стоит отметить, что кроме персонализации поиска для RTMR можно найти и другие применения. В большинстве случаев применяемые в Поиске алгоритмы можно перестроить на работу в режиме реального времени. Например, с его помощью можно улучшить качество поиска по свежим документам, публикациям в СМИ и блогах. Ведь ранжирование свежих документов зависит не только от скорости их обхода и индексации, это не самый сложный процесс и в большинстве случаев наш робот уже достаточно давно справляется с этим за несколько секунд. Однако значительная часть данных для ранжирования берется из внешних по отношению к документу источников информации, и для агрегации этих данных используется MapReduce. Как уже говорилось выше, ограничения методов батч-обработки не позволяют производить агрегацию быстрее, чем за 20-30 минут. Поэтому без RTMR часть внешних сигналов для свежих документов приходит с запаздыванием.
Подстройку поисковых подсказок тоже можно сделать моментальной. Тогда предлагаемые пользователю варианты запроса будут зависеть от того, что он искал несколько секунд назад.
Так как наша система еще достаточно молода, в ближайших планах у нас расширение парадигмы MapReduce: добавление в нее новых интерфейсов, заточенных специально под работу в реальном времени. Например, операций, способных способных делать предварительную неполную предагрегацию.
Кроме того, мы планируем произвести унифицированное для MapReduce и RTMR декларативное описание потоков данных и графа вычислений. Стадии RTMR-вычислений для разных ключей в отличие от MapReduce работают непоследовательно, а значит, последовательный запуск стадий из кода теряет всякий смысл.
